[0004] At present, multi-source heterogeneous data sharing mainly faces the following difficulties: ①Achievability refers to the difficulty for users to obtain data; due to the complexity and variety of multi-source heterogeneous data structures, the workload of data transmission is relatively large, and users can only To obtain multi-source heterogeneous data resources
In the past, a large amount of application data was developed for a single machine or a local area network, which resulted in a large number of legacy data resources that cannot be directly accessed on the Internet. How to access these resources on the Internet needs to be considered, and how to bridge multi-source heterogeneous data How to use the Internet protocol to transmit multi-source heterogeneous data; how users can find the system on the Internet and access legacy multi-source heterogeneous data through this system; the format of multi-source heterogeneous data obtained by users How, whether it can be applied directly or after conversion, there is no effective solution yet
②Interoperability refers to the difficulty for users to understand data; due to differences in product development and business strategies, different application data have clear boundaries, making it difficult for users to understand and use multi-source heterogeneous data
The key to multi-source heterogeneous data interoperability is to solve the heterogeneous problem of multi-source heterogeneous data, and data has syntax and semantics, how to discuss the problem of data heterogeneity in layers, and solve the problem of syntactic differences, semantic differences and fusion in the Internet environment difference problem, there is currently no effective solution
③ Ease of use refers to how easy it is for users to process multi-source heterogeneous data; many multi-source heterogeneous data products provide a secondary development platform for users to construct their own applications to meet various needs; applications in the Internet environment The construction method has also expanded from the single-machine single-task mode to the multi-task distributed computing mode. The potential user market cannot be monopolized by a few manufacturers, and it is difficult to provide services for specific applications. This requires an open data processing framework to provide data elements and services. elements, and then complete the task through the integration and application of the elements. There is no effective solution yet
[0008] The management of traditional data centers has the following defects: ① low utilization rate and poor flexibility; ② poor scalability; ③ chimney management; ④ high cost and increased energy consumption
[0011] Compared with foreign countries, the application of domestic unique identifiers is still in its infancy, and there are mainly the following defects: ①The role of domestic custom unique identifiers is only the unique number of digital objects, and the formulation and use of unique identifiers lack specifications. The unique identifiers used by literature manufacturers are different, and there is no unified standard; ②The unique identifiers only function within the scope of their respective resources, and once they are separated from their respective databases, their unique identifiers cannot reveal any characteristics of the literature;③ The application level of the unique identifier is relatively low, and its role is limited to the identification of internal digital objects. The analysis system and management mechanism related to the application of the unique identifier have not been established, and the resource sharing of various digital document manufacturers cannot be realized; ④ Unique There is no hierarchical relationship in the identification, and a unified identification method is adopted for all data, which cannot reflect the level and relationship between data
2) The materialization processing method is mainly to establish a central database and copy the data of each data source to the data center. Its advantage is that it is easy to obtain better integrated query performance, but it cannot flexibly adapt to changes in requirements
②Unified representation of data objects. Due to the differentiation of data structures, there are many ways to represent data objects, which makes the data integration process complex and diverse.
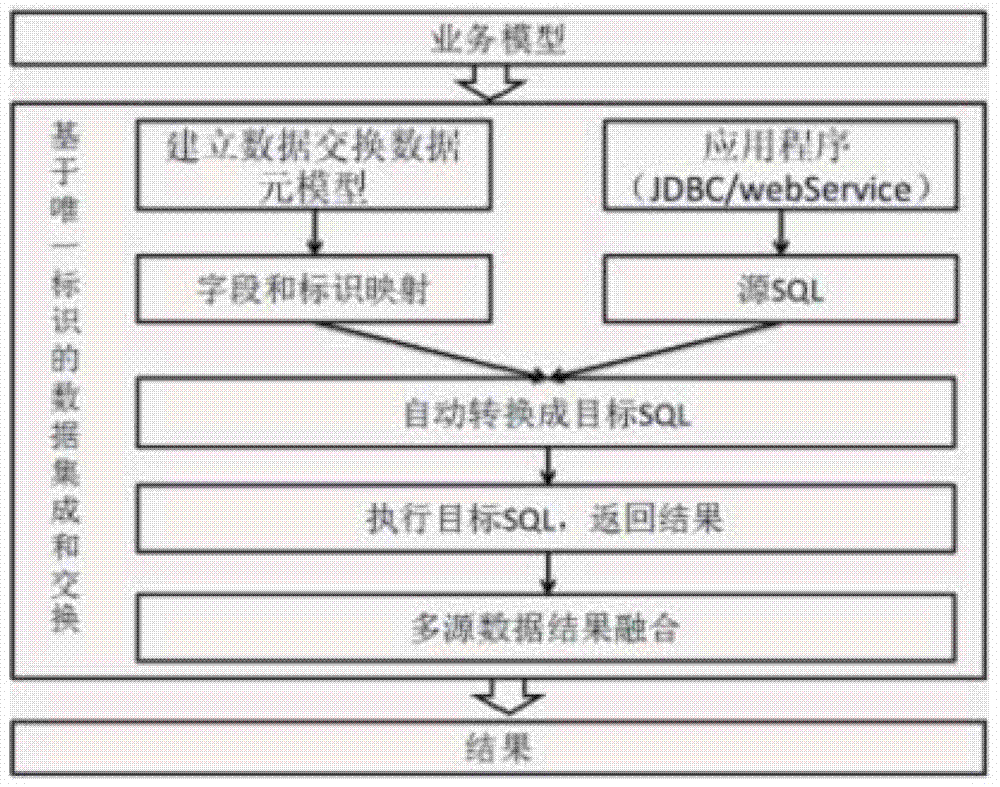
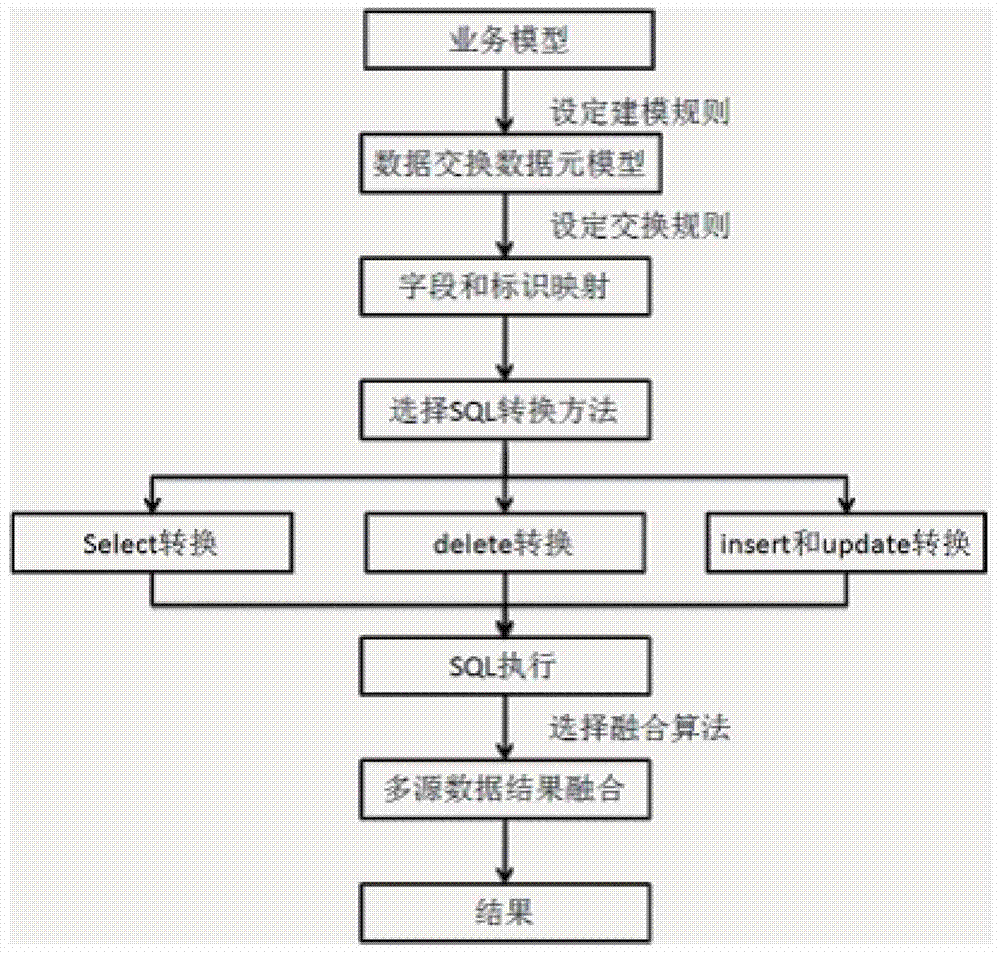
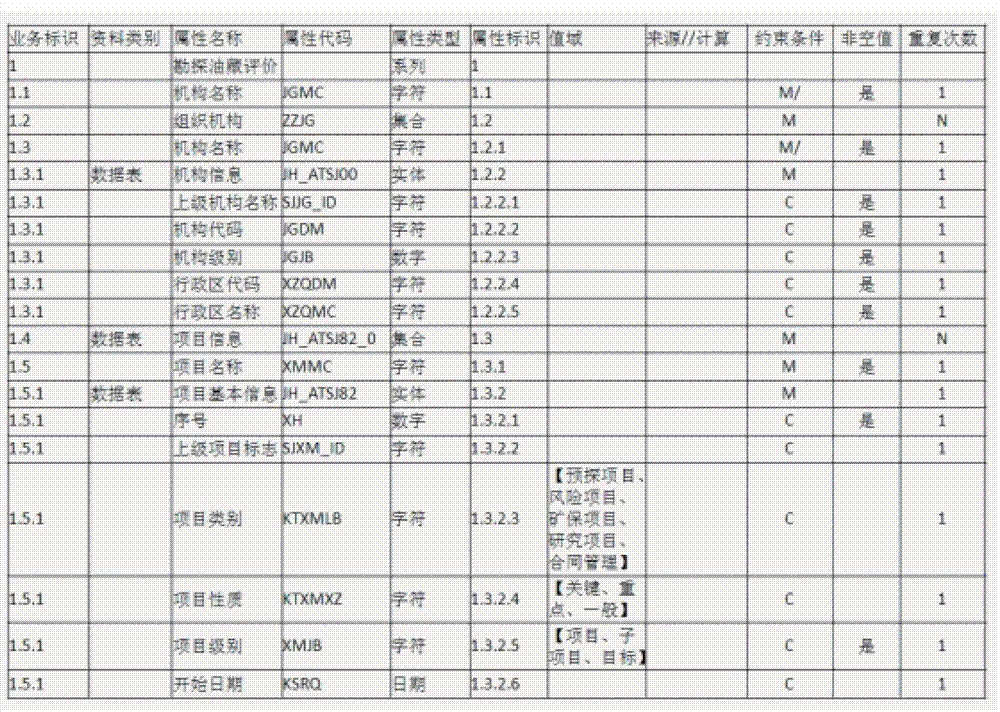
[0016] Currently there is no data integration and exchange method to effectively solve the above problems



 Login to View More
Login to View More  Login to View More
Login to View More