

A Parallel Loading Method of Power Grid Time Series Big Data
A big data and time series technology, applied in the field of parallel loading of massive historical time series data, can solve problems such as inability to load in parallel, consume a lot of time, and network communication overhead, etc., and achieve the effect of efficient parallel loading and reduced time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0018] The present invention will be described in further detail below in conjunction with the accompanying drawings and embodiments.
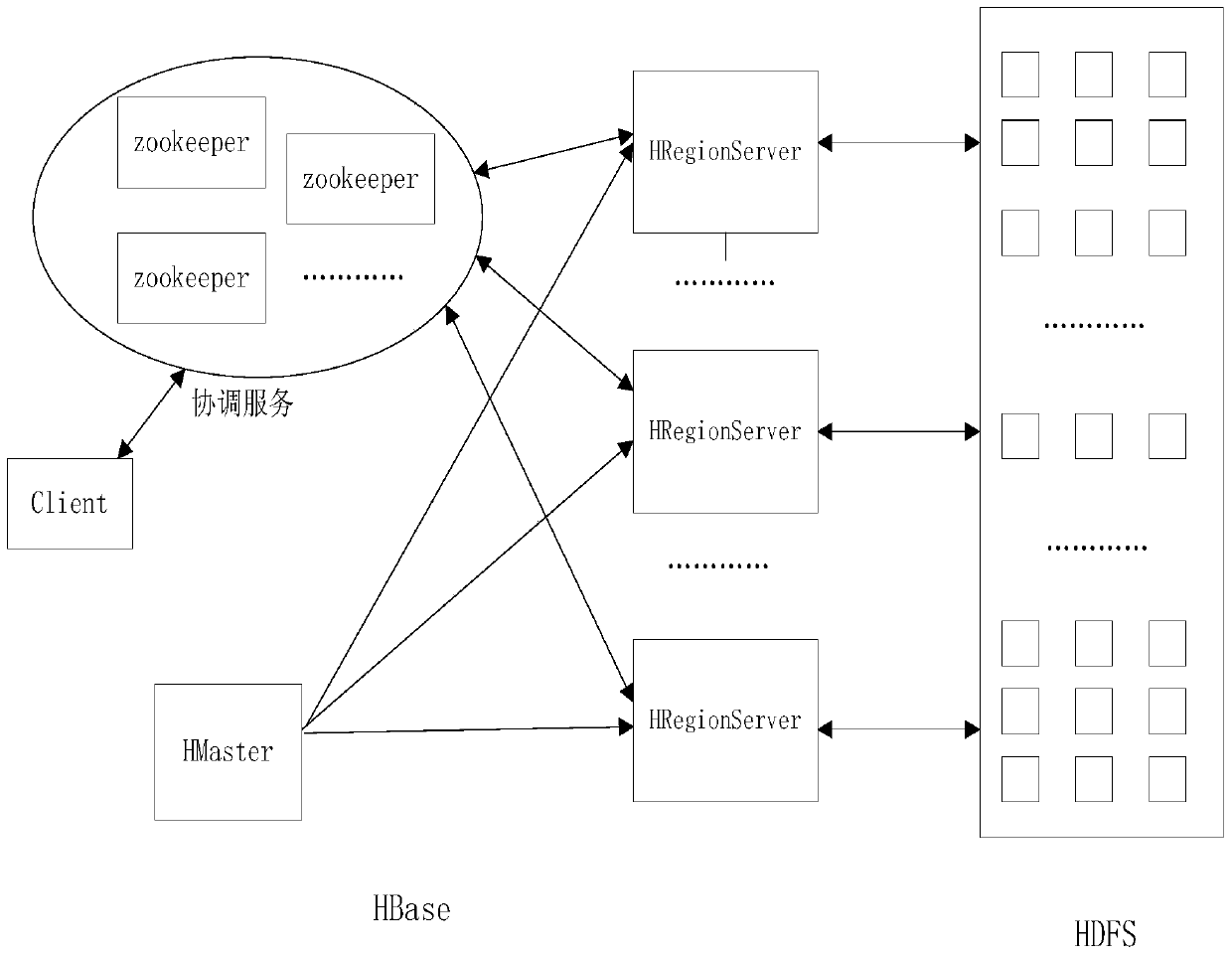
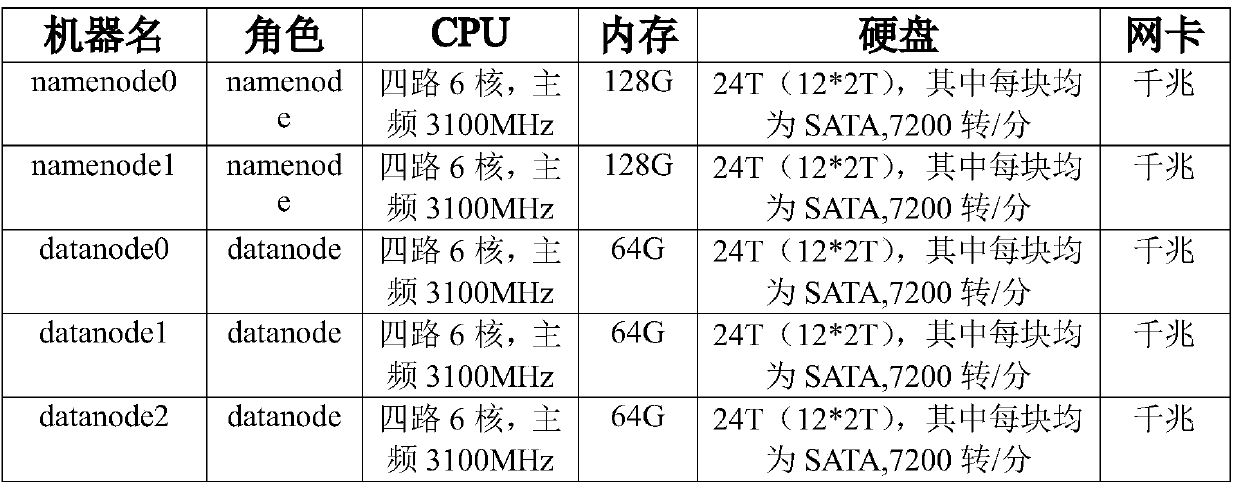
[0019] This embodiment describes the present invention by using an application example in a power grid business scenario. Assume that the following cluster based on Hadoop and HBase consists of 5 machines and a high-availability HA configuration is performed on the cluster. The configuration of each machine is shown in Table 1. In this application scenario, there are 600,000 measurement points, the data collection frequency is 60 frames / min, and each data record collected is about 70 bytes, so the 600,000 measurement points will generate 3.3T bytes per day (24 hours). The data. The following describes the implementation of the method by taking loading 3.3T data into a big data system as an example.
[0020]
[0021] Table 1 Configuration of each machine in the cluster
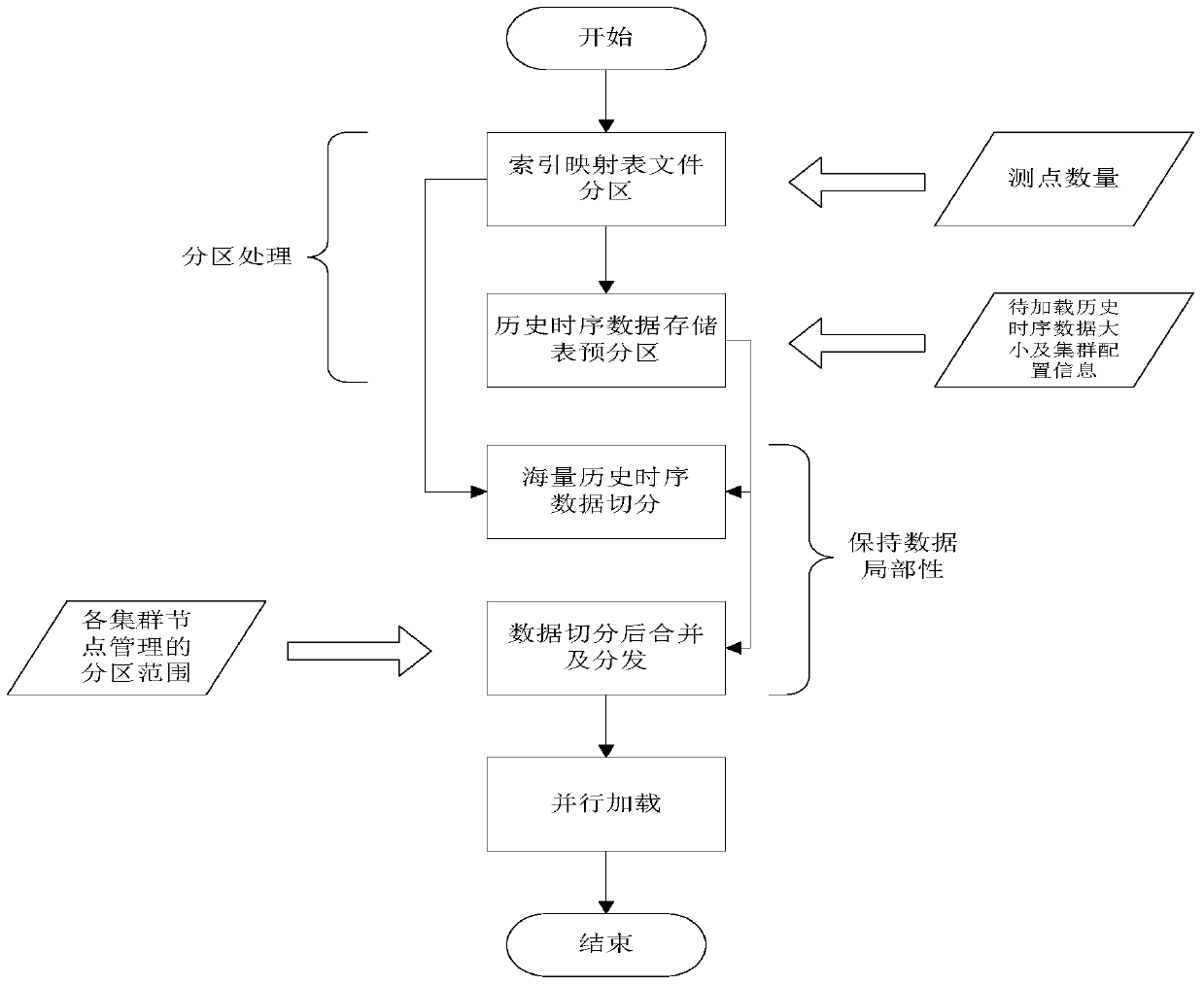
[0022] The flow chart of the inventive method is as figure 2 Shown...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More