

Non-recursive clustering algorithm based on quicksort (NR-CAQS) suitable for large data
A technology of large-scale data and clustering methods, applied in database models, relational databases, electronic digital data processing, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
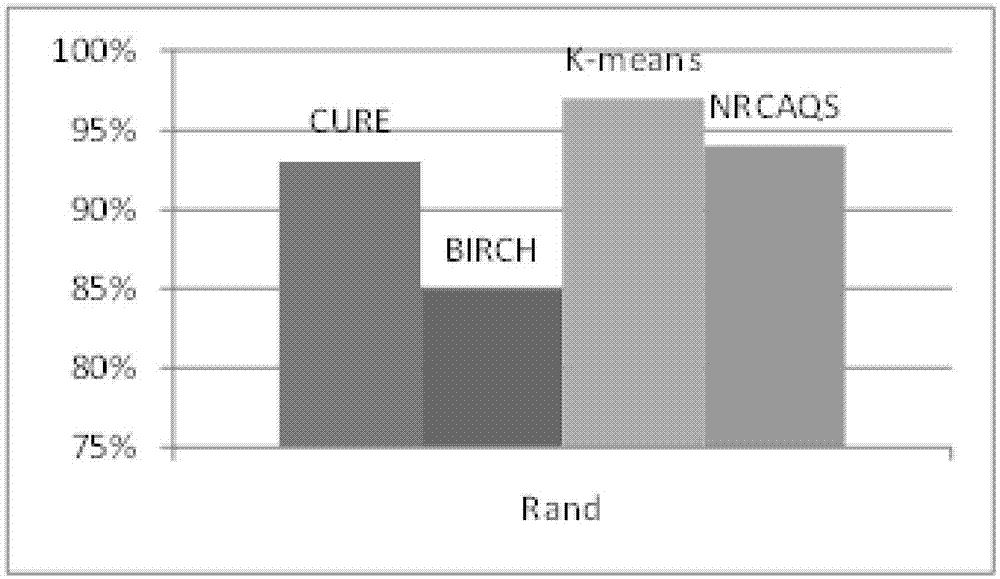
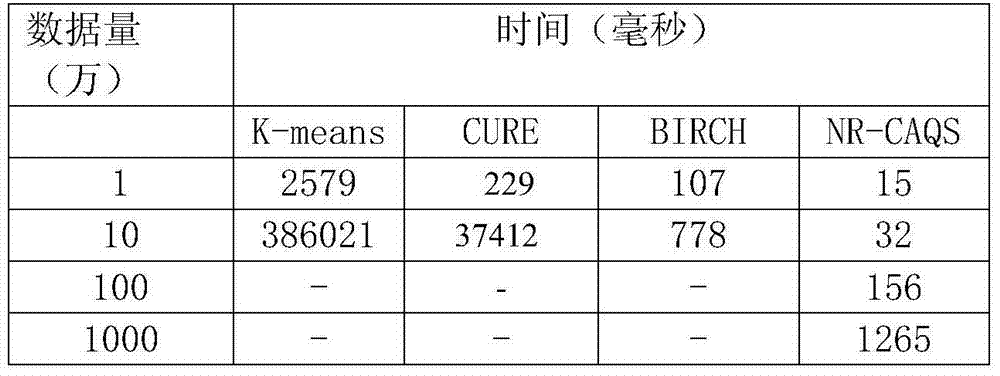
Method used
Image

Examples
Embodiment Construction
[0022] The present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments.
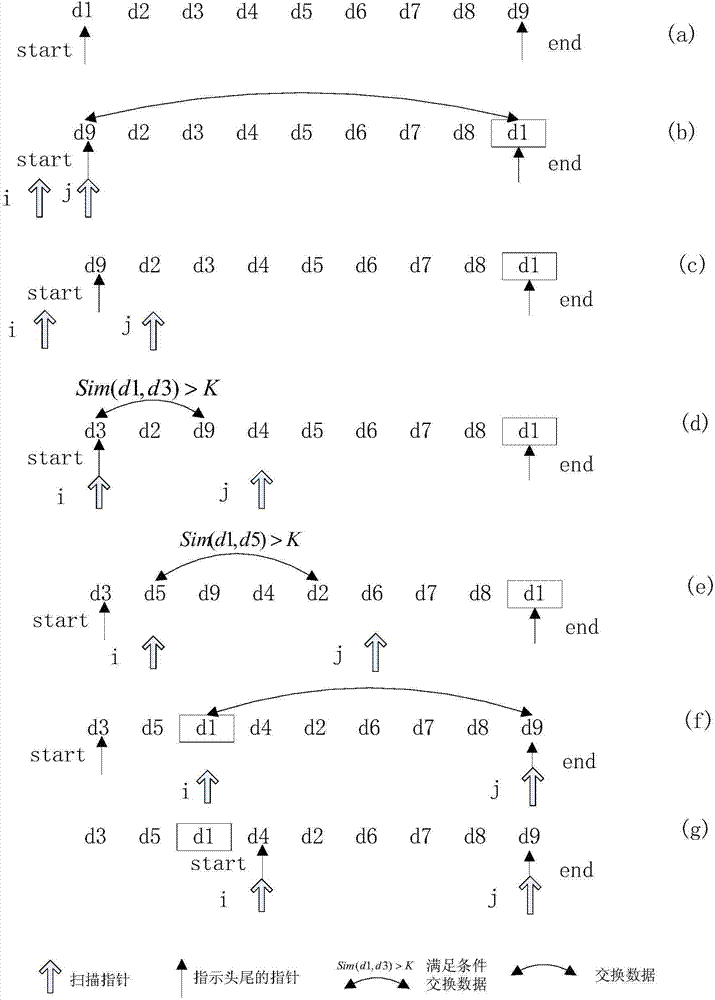
[0023] In the following example, the data sequence D={d1, d2, d3, d4, d5, d6, d7, d8, d9}, there are four known clusters, namely C={C_1={d1, d3, d5 }, C_2={d2,d6}, C_3={d4,d9}, C_4={d7,d8}}, and the similarity between the data in the cluster is greater than or equal to 0.8, and the similarity between the data in the cluster is less than 0.8. In order to obtain correct clustering results, the similarity threshold input during the specific operation is set to 0.8. The steps to use the quicksort-based non-recursive clustering method on this data sequence are as follows:
[0024] Step 1: Input the user similarity threshold K=0.8 and the initial data sequence D to be processed containing 9 data samples;
[0025] Step 2: Define the indicator pointers of the head and tail of the data sequence to be processed as start and end respectively, and ass...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More