

Regular expression based URL filtering method
A filtering method and text filtering technology, which are applied in special data processing applications, using information identifiers to retrieve web data, instruments, etc., can solve the problem that crawlers stop data acquisition, crawlers cannot obtain correct data, and crawler programs have low coverage and other issues to achieve the effect of accurate search results
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
[0020] The present invention will be further described below.
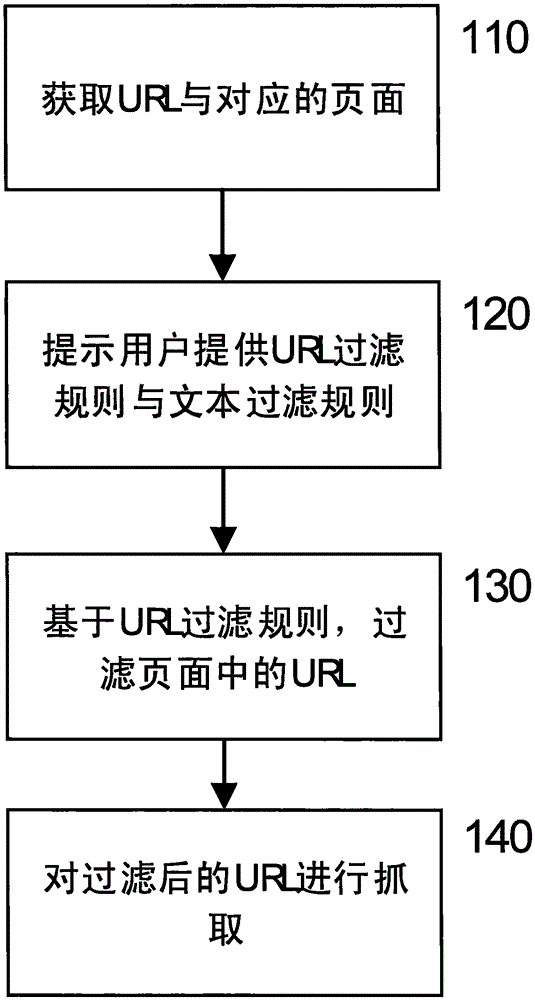
[0021] figure 1 A flow chart of a URL filtering method according to an embodiment of the present invention is shown. see figure 1 , according to the URL filtering method of the present invention, comprising: Step 110, acquiring the URL to be captured and the page corresponding to the URL to be captured. The URL to be grabbed can be specified by the user, or the URL to be grabbed can be obtained through configuration files or scripts. Step 120, showing the web page corresponding to the URL to be captured to the user, and prompting the user to request the user to provide URL filtering rules and / or text filtering rules for filtering the URL, and use the filtered URL to perform web page crawling Pick. In response to the URL filtering rules provided by the user, URLs in the page are filtered based on the URL filtering rules provided by the user (step 130). As an example, the page obtained in step 110 may contain m...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More