

Multithreading-based web crawler system and web crawling method thereof
A web crawler, multithreading technology, applied in the field of web crawler systems based on multithreading, can solve problems such as low efficiency, slow crawling speed, difficult maintenance, etc., and achieve the effect of improving the efficiency of concurrency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
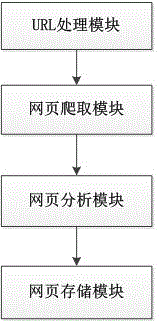
[0046] Such as figure 1 As shown, a multithread-based web crawler system includes a URL processing module, a webpage crawling module, a webpage analysis module and a webpage storage module.
[0047] The URL processing module obtains the host name, port number, and file name of each URL through URL class processing.
[0048] The general form of URL is: : / / : / . In this program, it can be made simple, so a class for storing URLs is designed, which includes Host (host name), Port (port), File (file path), Fname (this is for this web page called name). The following code is all the members of the URL class and its member functions:
[0049] classURL
[0050] {
[0051] public:
[0052] URL(){}
[0053] voidSetHost(conststring&host){Host=host;}
[0054] stringGetHost(){returnHost;}
[0055] voidSetPort(intport){Port=port;}
[0056] intGetPort(){returnPort;}
[0057] voidSetFile(conststring&file){File=file;}
[0058] stringGetFile(){returnFile;}
[0059] voidSetFname(const...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More