Word frequency based skip language model training method
What is AI technical title?
AI technical title is built by Patsnap AI team. It summarizes the technical point description of the patent document.
A language model and training method technology, applied in the field of Chinese statistical language model training, can solve the problem of lack of statistical language model OOV and so on
Active Publication Date: 2016-12-28
UNIV OF ELECTRONICS SCI & TECH OF CHINA
View PDF9 Cites 15 Cited by
Summary
Abstract
Description
Claims
Application Information
AI Technical Summary
This helps you quickly interpret patents by identifying the three key elements:
Problems solved by technology
Method used
Benefits of technology
Problems solved by technology
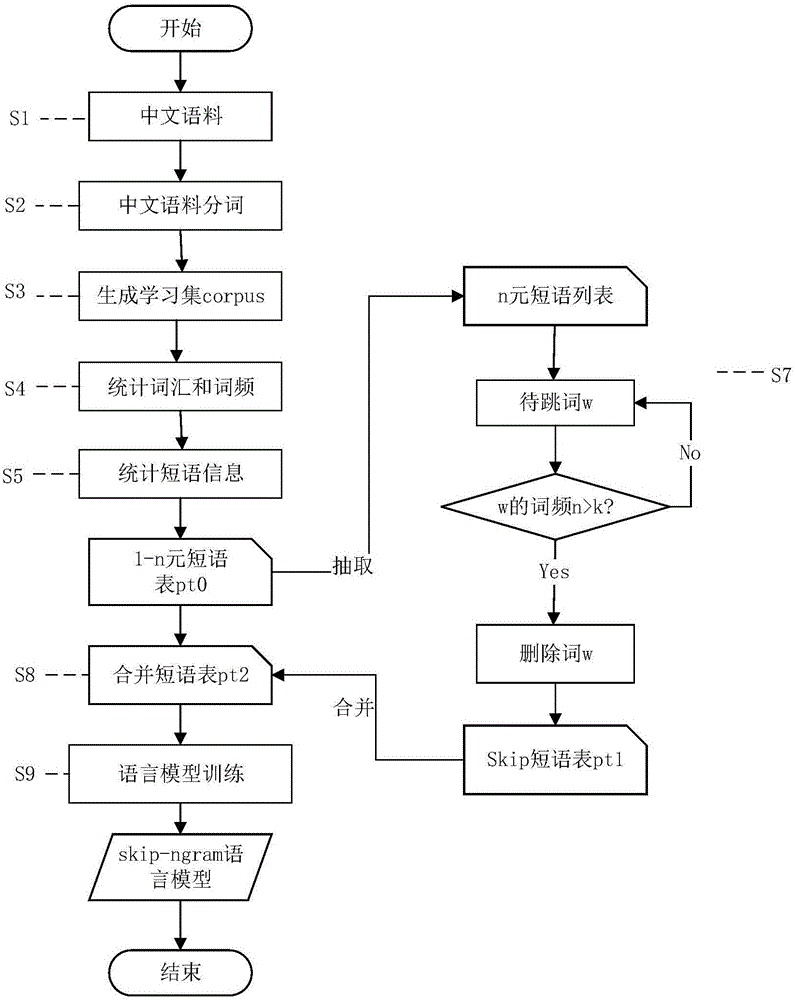
[0010] The present invention provides a kind of training method of skip language model based on word frequency in view of above-mentioned deficiencies, solves the problem of OOV of statistical language model caused by lack of corpus in the prior art
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View more
Image
Smart Image Click on the blue labels to locate them in the text.
Viewing Examples
Smart Image
Click on the blue label to locate the original text in one second.
Reading with bidirectional positioning of images and text.
Smart Image
Examples
Experimental program
Comparison scheme
Effect test
example 1
[0077] Example 1, the number of words in the longest vocabulary in the dictionary is L = 5, and the positive maximum matching word segmentation is performed for the "Planning Developer Circle of the Ministry of Land and Resources":
[0078] The first round of search: "Ministry of Land and Resources", scan the dictionary, there is this word;
[0079] Round 2 search: "plan developer", scan dictionary, no such word;
[0080] "planned development", scan dictionary, no such word;
[0081] "Scheduled to open", scan the dictionary, there is no such word;
[0082] "plan", scan the dictionary, there is the word;
[0083] The third round of search: "developer circle", scan the dictionary, no such word;
[0084] "Developer", scan the dictionary, there is the word;
[0085] The fourth round of search: "circle", scan the dictionary, there is the word;
[0086] The positive maximum matching word segmentation result Rf is "Ministry of Land and Resources Planning Developer Circle".
[0...
example 2
[0097] Example 2: Take a sentence in the corpus as an example, the sentence after the word segmentation in step S2: "Ili, located in the northwest border, is an important window for my country's opening to the outside world. Since the reform and opening up, Yili's economy has developed rapidly, and people's living standards have rapidly improved. "
[0098] The example sentence is processed in step S3, and the result obtained is: " Yili, located on the northwestern border, is an important window for my country's opening to the outside world. Since the reform and opening up, Yili's economy has achieved rapid development and people's living standards have improved rapidly. ".
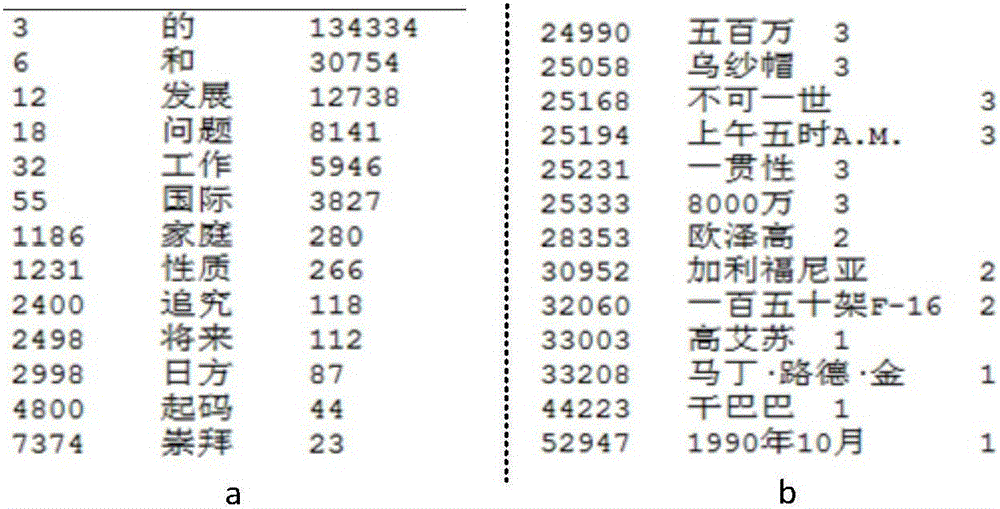
[0099] S4. Count the vocabulary and word frequency in the learning set corpus, and generate the Chinese vocabulary wt. Traversing the sentence processed in step S3, every time a new word a is encountered, write a into the Chinese vocabulary, and initialize the number of occurrences c to 1; when traversin...
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
PUM
Login to View More
Abstract
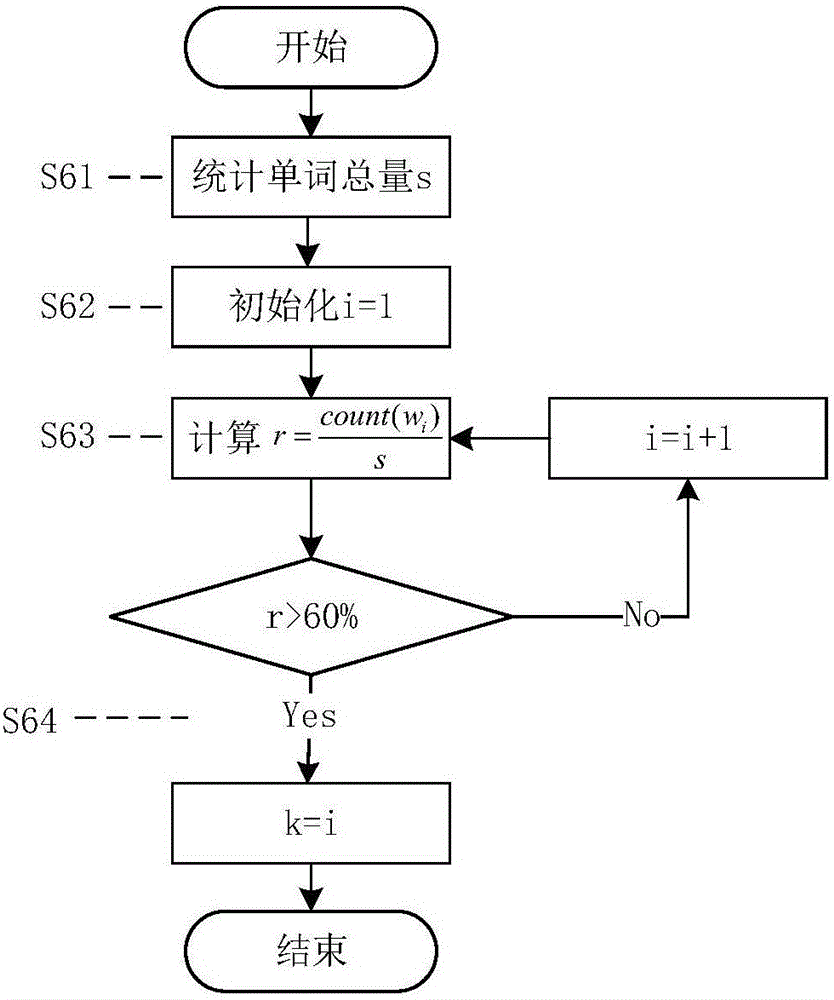
The invention discloses a word frequency based skip language model training method, relates to the technical field of machine translation and aims at solving the OOV problem of a statistical language model caused by linguistic data shortage in the prior art. The word frequency based skip language model training method comprises the steps that Chinese sentences are collected; the Chinese sentences are segmented; a learning set corpus is generated; statistics is conducted on vocabulary and word frequency in the learning set corpus to generate a Chinese vocabulary wt; statistics is conducted on phrases and the emerging times of phrases in the corpus to generate a 1-n Chinese phrase table pt0; a selective skip standard k is set, and k judgment is performed according to the statistical results of the word frequency in the Chinese vocabulary wt, and when the sum of the number of all the vocabulary with the emerging times k not greater than i accounts for above 60% of the number of all the vocabulary, k = i; linguistic model training is performed according to a Chinese sentence table pt2 to obtain a skip-ngram linguistic model. The word frequency based skip language model training method is used for obtaining a linguistic model probability table.
Description
technical field [0001] A word frequency-based skip language model training method for obtaining a language model probability table relates to the technical field of machine translation, in particular to the technical field of a corpus-based Chinese statistical language model training method. Background technique [0002] Language model is one of the basic probability models in statistical machine translation technology. It is used to evaluate the possibility of a certain word sequence in the translated sentence, which is related to the fluency of the translated sentence (translated word sequence). The higher the probability of the language model, the more legal, fluent and consistent the translation is. Assuming that w1 and w2 represent two words, p(w2|w1) represents the probability of w2 appearing behind w1, that is, the probability that the phrase w1w2 may appear; according to linguistic knowledge, the possibility of the phrase "eat noodles" appearing will be significantly...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
Application Information
Patent Timeline
Application Date:The date an application was filed.
Publication Date:The date a patent or application was officially published.
First Publication Date:The earliest publication date of a patent with the same application number.
Issue Date:Publication date of the patent grant document.
PCT Entry Date:The Entry date of PCT National Phase.
Estimated Expiry Date:The statutory expiry date of a patent right according to the Patent Law, and it is the longest term of protection that the patent right can achieve without the termination of the patent right due to other reasons(Term extension factor has been taken into account ).
Invalid Date:Actual expiry date is based on effective date or publication date of legal transaction data of invalid patent.



 Login to View More
Login to View More  Login to View More
Login to View More