

Terminal-based paper duplicate checking method, terminal and storage medium
A paper and terminal technology, applied in the computer field, can solve problems such as time-consuming and troublesome modification operations, and achieve the effect of saving time and facilitating reference modification operations.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
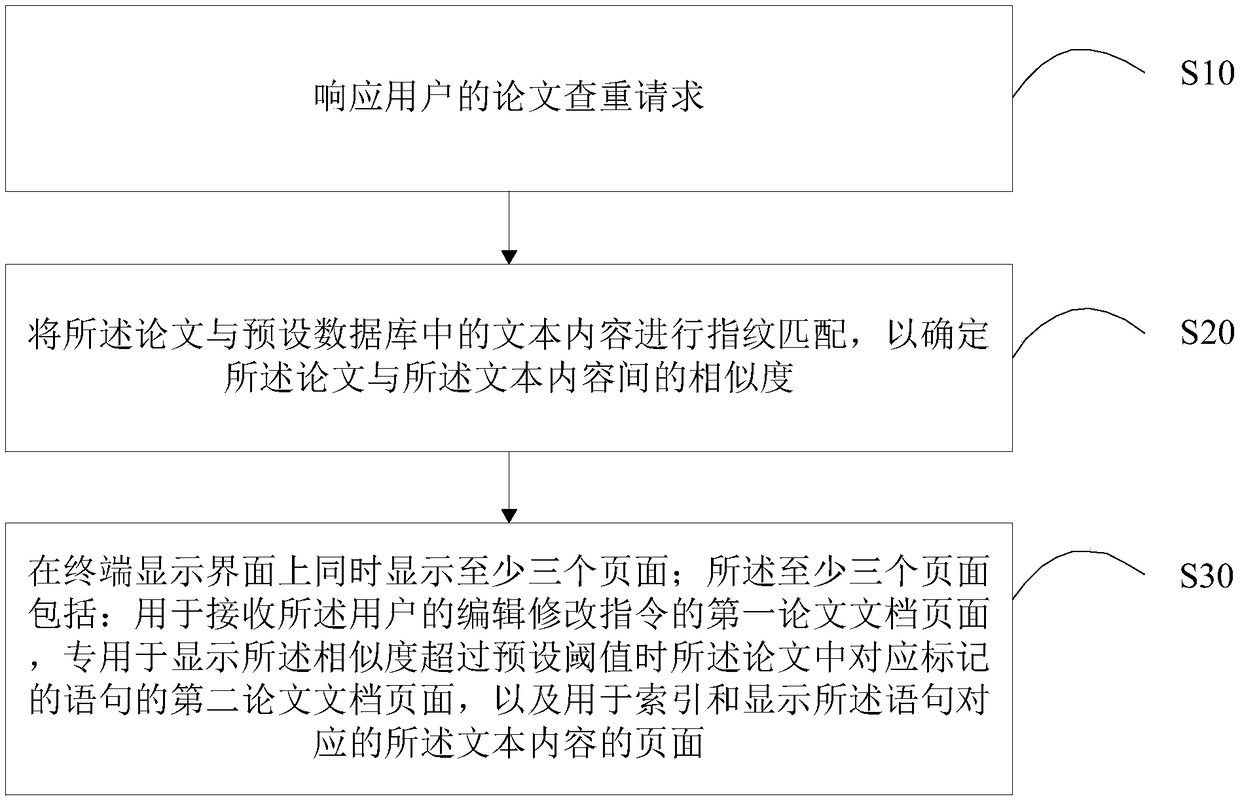
[0052] In order to facilitate a better understanding of the present invention, the present invention will be further explained below in conjunction with the accompanying drawings of related embodiments. Embodiments of the invention are shown in the drawings, but the invention is not limited to the preferred embodiments described above. Rather, these embodiments are provided so that the disclosure of the invention will be more thorough.
[0053] The logic and / or steps represented in the flowcharts or otherwise described herein, for example, can be considered as a sequenced listing of executable instructions for implementing logical functions, can be embodied in any computer-readable medium, For use with instruction execution systems, devices, or devices (such as computer-based systems, systems including processors, or other systems that can fetch instructions from instruction execution systems, devices, or devices and execute instructions), or in conjunction with these instruct...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More