A video sequence expression recognition method based on mixed deep learning
A video sequence and facial expression recognition technology, which is applied in character and pattern recognition, acquisition/recognition of facial features, instruments, etc., can solve problems such as dynamic changes in video sequences that are not considered
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0063] The technical solutions of the present invention will be further described below in conjunction with the accompanying drawings and embodiments.
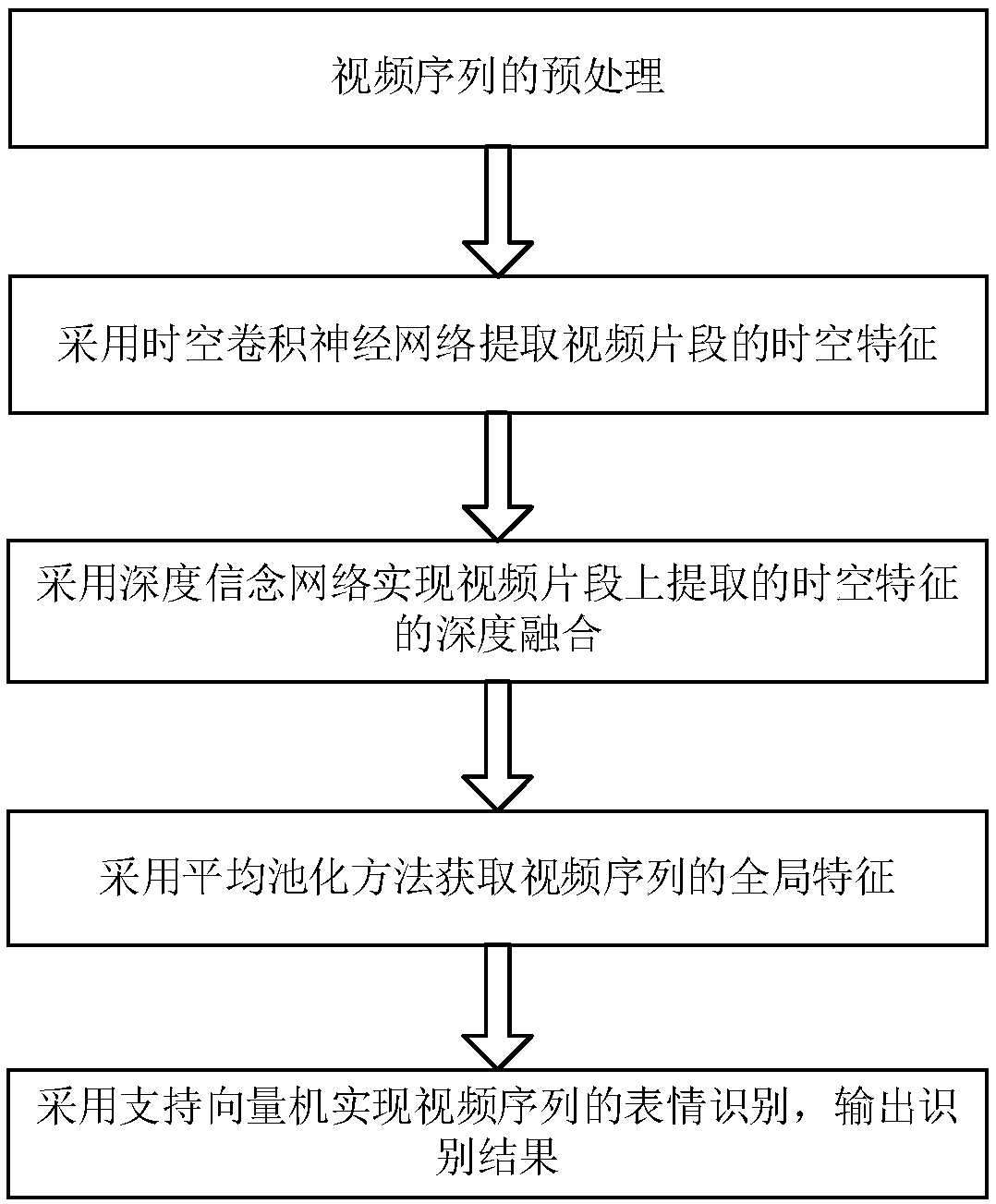
[0064] figure 1 The block diagram of this system mainly includes:
[0065] Step 1: preprocessing of video sequences;
[0066] Step 2: Using spatio-temporal convolutional neural network to extract spatio-temporal features of video clips;
[0067] Step 3: Deep fusion of spatio-temporal features extracted from video clips using deep belief network;
[0068] Step 4: Use the average pooling method to obtain the global features of the video sequence;
[0069] Step 5: Use the support vector machine to realize the expression recognition of the video sequence, and output the recognition result.
[0070] One, the realization of each step of this system block diagram, concrete expression is as follows in conjunction with embodiment:
[0071] (1) Preprocessing of video sequences
[0072] From the RML video sequence expression databa...
PUM
 Login to view more
Login to view more Abstract
Description
Claims
Application Information
 Login to view more
Login to view more - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap