

A Chinese word segmentation method based on bi-directional long-short time memory network model
A long- and short-term memory, Chinese word segmentation technology, applied in biological neural network models, special data processing applications, instruments, etc., can solve the problems of not being able to use the future text information of sentences, prone to overfitting, etc., to achieve good word segmentation and improve accuracy. rate effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
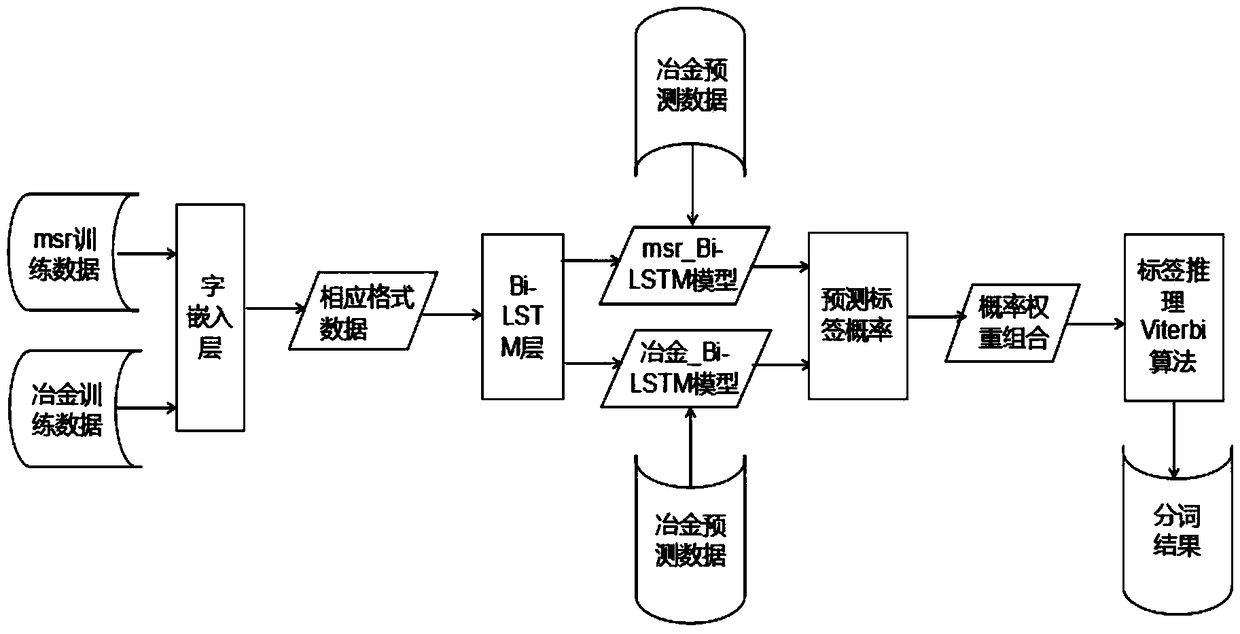
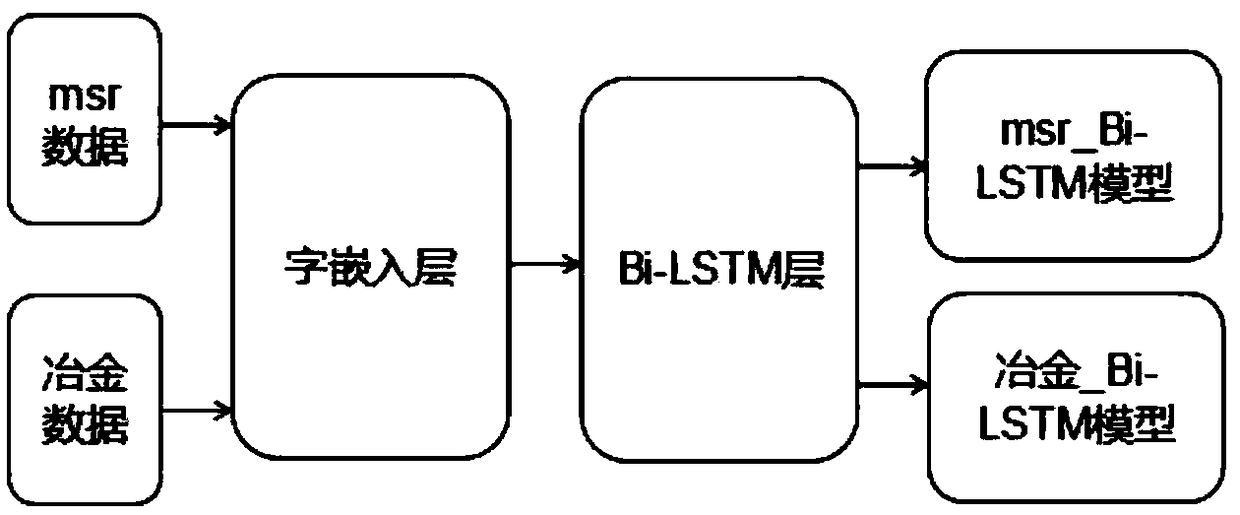
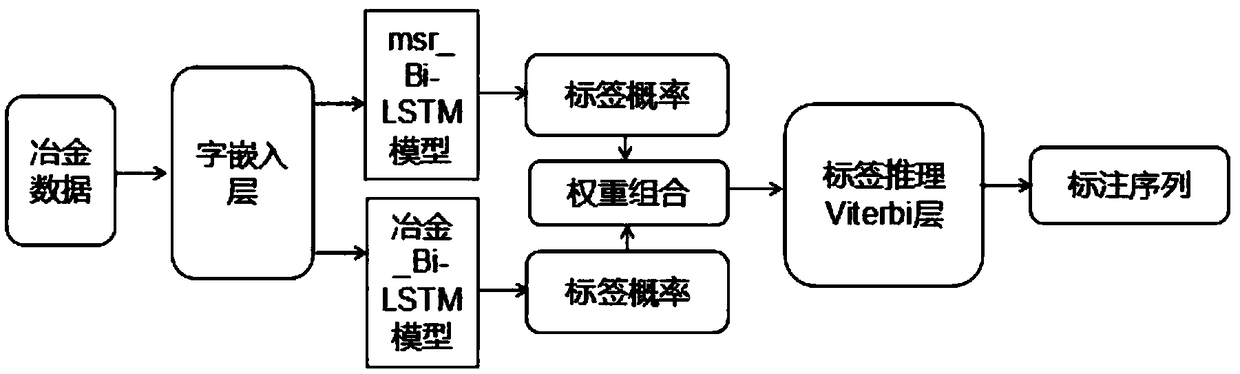
[0036] Embodiment 1: as figure 1 As shown, it is the workflow of the Chinese word segmentation method in the field of metallurgy based on the two-way long-short-term memory network model. The specific steps are:
[0037] Step1: Due to the lack of authoritative corpus in the metallurgical information field, the data from the metallurgical information network was crawled to obtain the text data set in the metallurgical field, and the text data set was divided into a training set and a test set, and then the training set was preprocessed. The specific processing process is to use the BMES tagging method to tag the Chinese characters in the training set, as shown in Table 1. For multi-word words, B is the label of the first word in the multi-word word, and M is the label for removing the first word in the multi-word word. The label of the word and other words after the last word, E is the label of the last word in the multi-word, S is the label of the single word, the data set msr...
Embodiment 2
[0058] Embodiment 2: the present embodiment method is the same as embodiment 1, and the difference is that the present embodiment is applied in the non-metallurgical field, and the selected text is marked with four word positions (BEMS), and the results obtained are as shown in table 7:
[0059] Table 7 four-lexeme tag form
[0060]
[0061] Segment the labeled data according to the punctuation marks, and use the arrays data and label to represent the results after segmentation, as shown in Table 8:
[0062] Table 8 data and label data format
[0063]
[0064] The data data group includes each Chinese character, the label data group includes the label corresponding to each Chinese character, and then the data data group and the label data group are digitized separately, and each Chinese character in the data data group is used for the first time the Chinese character appears The sequential numbers are represented and stored in d['x'], and the labels of the label data gr...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More