

A method and system for data dependency mining based on distributed computing
A distributed computing, data-dependent technology, applied in the field of data processing, can solve problems such as low performance and many omissions in mining, and achieve the effect of reducing the amount of computation
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
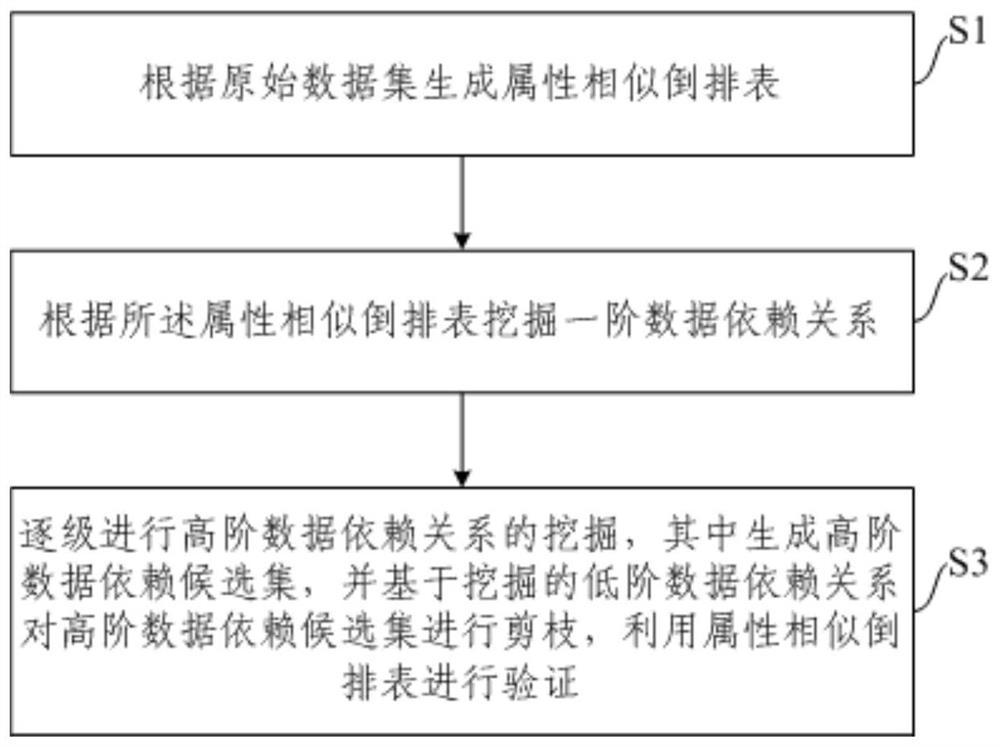
[0064] Such as figure 1 As shown, the distributed computing-based data dependency mining method provided in Embodiment 1 of the present invention may include the following steps:
[0065] Step S1: Generate attribute similarity posting list according to the original data set. This step is a data reallocation step. Wherein, each row in the attribute similar posting table corresponds to a data pair in the original data set, and this row records the attribute number of the pair of data pairs satisfying the similarity constraint.
[0066] Step S2: Mining first-order data dependencies according to the attribute similar posting list. This step is a first-order dependency mining step.
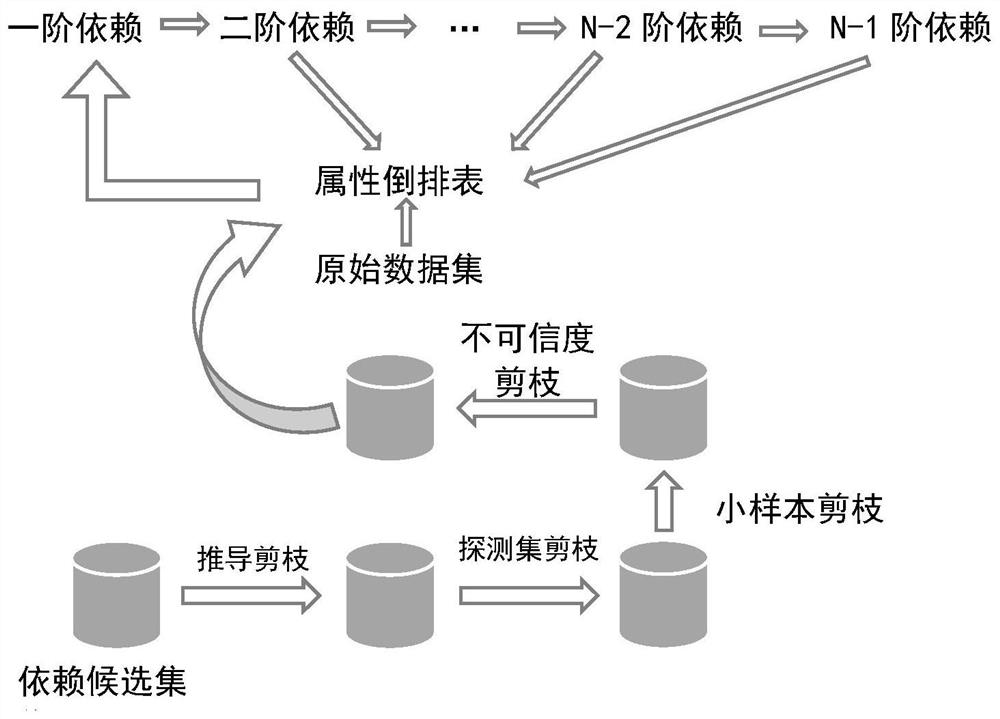
[0067] Step S3: Mining high-order data dependencies step by step, in which high-order data dependency candidate sets are first generated, that is, all candidate relationships of k-order data dependencies are generated, and high-order data dependency candidates are generated based on the mined low-or...
Embodiment 2
[0075] On the basis of the distributed computing-based data dependency mining method provided in Embodiment 1 of the present invention, the specific implementation process of the data redistribution step is provided as follows:
[0076] The first step: because the different attributes of the data may have different formats and similar (or distance) functions, it is not convenient to carry out parallel processing. The present invention first converts the database stored by rows into several sub-datasets reorganized by columns. Specifically, a data ID is specified or generated for each piece of data in the original data set, and for each piece of data, the data ID, attribute number, and attribute value are stored as a triplet. After all the data is processed, it is redistributed according to the attribute number (corresponding to the ReduceByKey operation in the Spark framework), where each attribute number corresponds to a sub-database, which records the data ID and The value o...
Embodiment 3
[0154] On the basis of the distributed computing-based data dependency mining method provided in Embodiment 2 of the present invention, the specific implementation process of the first-order dependency mining step is as follows:
[0155] 1) For the data pair (i, j) in the attribute similar posting list, the attribute set A that satisfies the similarity constraint ij , generating a Cartesian product And aggregate the results into a first-order exclusion list.
[0156] 2) Eliminate the repeated elements in the first-order exclusion list to obtain the first-order data dependencies to be excluded;
[0157] 3) Use the Cartesian product to generate a candidate set of first-order data dependencies, and obtain a non-trivial candidate set of first-order data dependencies after eliminating diagonal elements;
[0158] 4) Subtracting the first-order data dependencies to be excluded from the candidate set of non-trivial first-order data dependencies to obtain the mined first-order data ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More