

Data reading and writing method and data reading and writing system
A technology of data reading and data writing, applied in the field of data technology data processing, can solve the problems of JDBC server suspended animation, occupying task scheduling time, slow speed, etc., to avoid slow writing speed, high throughput, and strong stability Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0043] The implementation of the present invention will be illustrated in detail below with reference to the accompanying drawings. The examples of the present invention are for further explaining the present invention, rather than limiting the protection scope of the present invention.
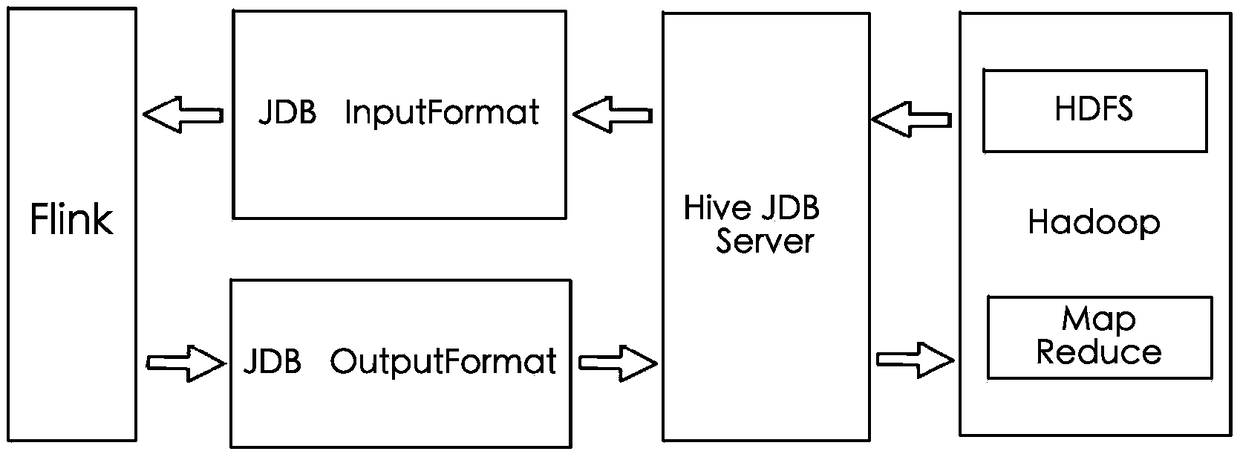
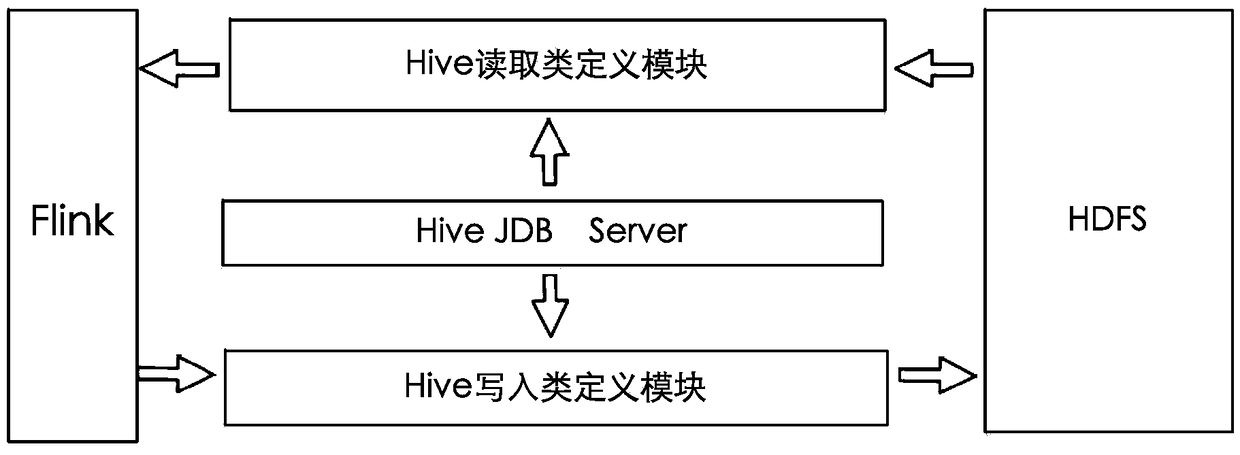
[0044] Please refer to figure 2 , image 3 As shown, this application proposes a method for the Flink platform to quickly read Hive, including:
[0045] Define the Hive data reading class, which implements the InputFormat interface of the Flink framework. In this embodiment, a Java program is used to define the Hive data reading class class HiveInputFormat implementsInputFormat.
[0046] Implement the configure method of the InputFormat interface of the Flink framework in the Hive data reading class;
[0047] In the implemented configure method, the following sub-steps are included:
[0048] Obtain the database connection instance of Hive through the JDBC connection string of Hive;
[0...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More