A caching strategy method in d2d network based on deep reinforcement learning
A reinforcement learning and network caching technology, applied in neural learning methods, biological neural network models, electrical components, etc., can solve the problems of high energy consumption, long delay, and low hit rate of cache content placement, and achieve low energy consumption and delay short-term effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
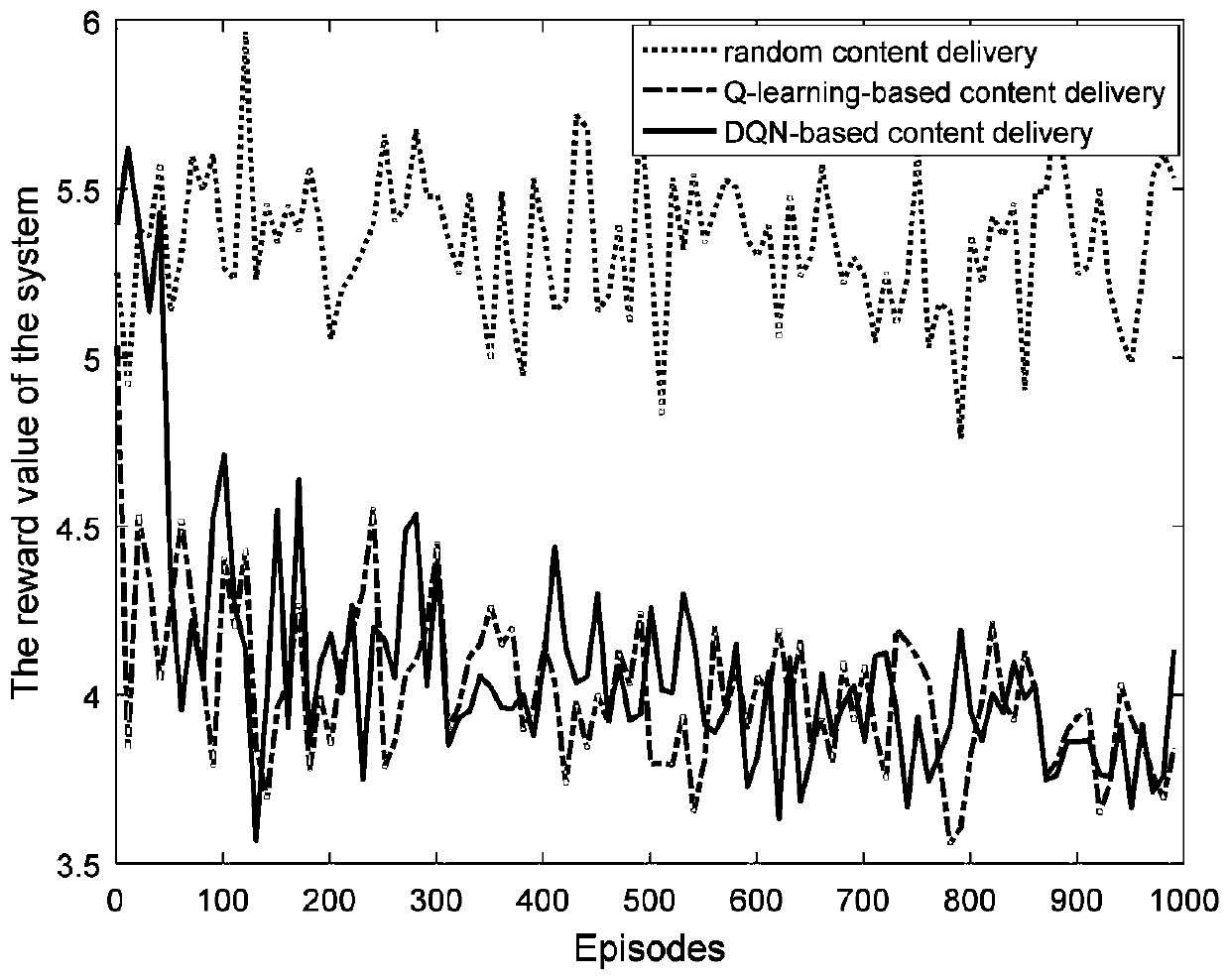
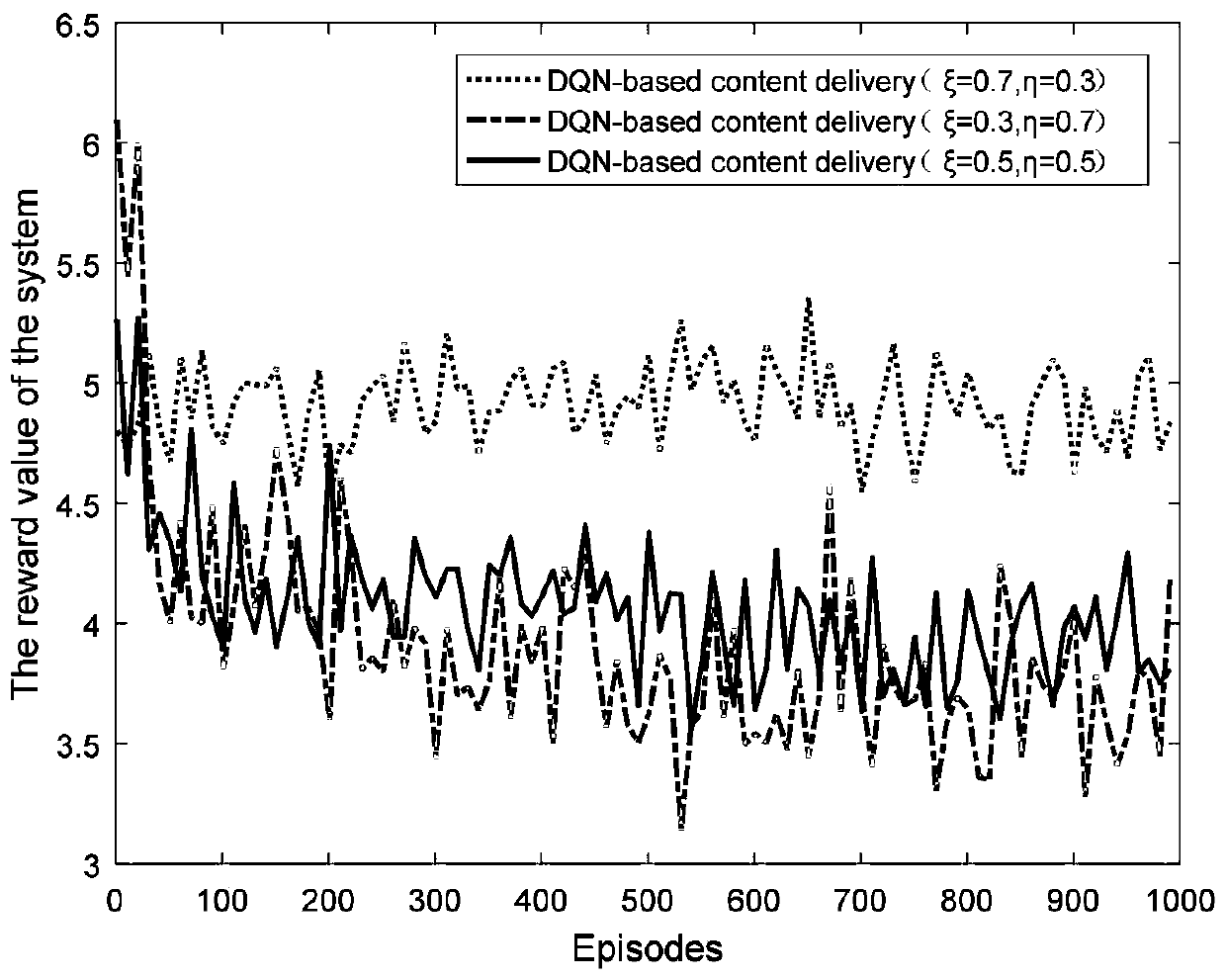
[0098] In this embodiment, a caching-enabled D2D network with 200 D2D users is considered, and selected content is distributed to D2D storage based on content popularity and user mobility prediction results. In order to simplify the simulation, in the deep reinforcement learning environment, the number of D2D users who satisfy user requests at each moment is set to a fixed value of 4, the distance d∈(0,4), the gain g∈(0,4), and P=1. In practical applications, this variation varies with time, but does not affect the accuracy of the algorithm.
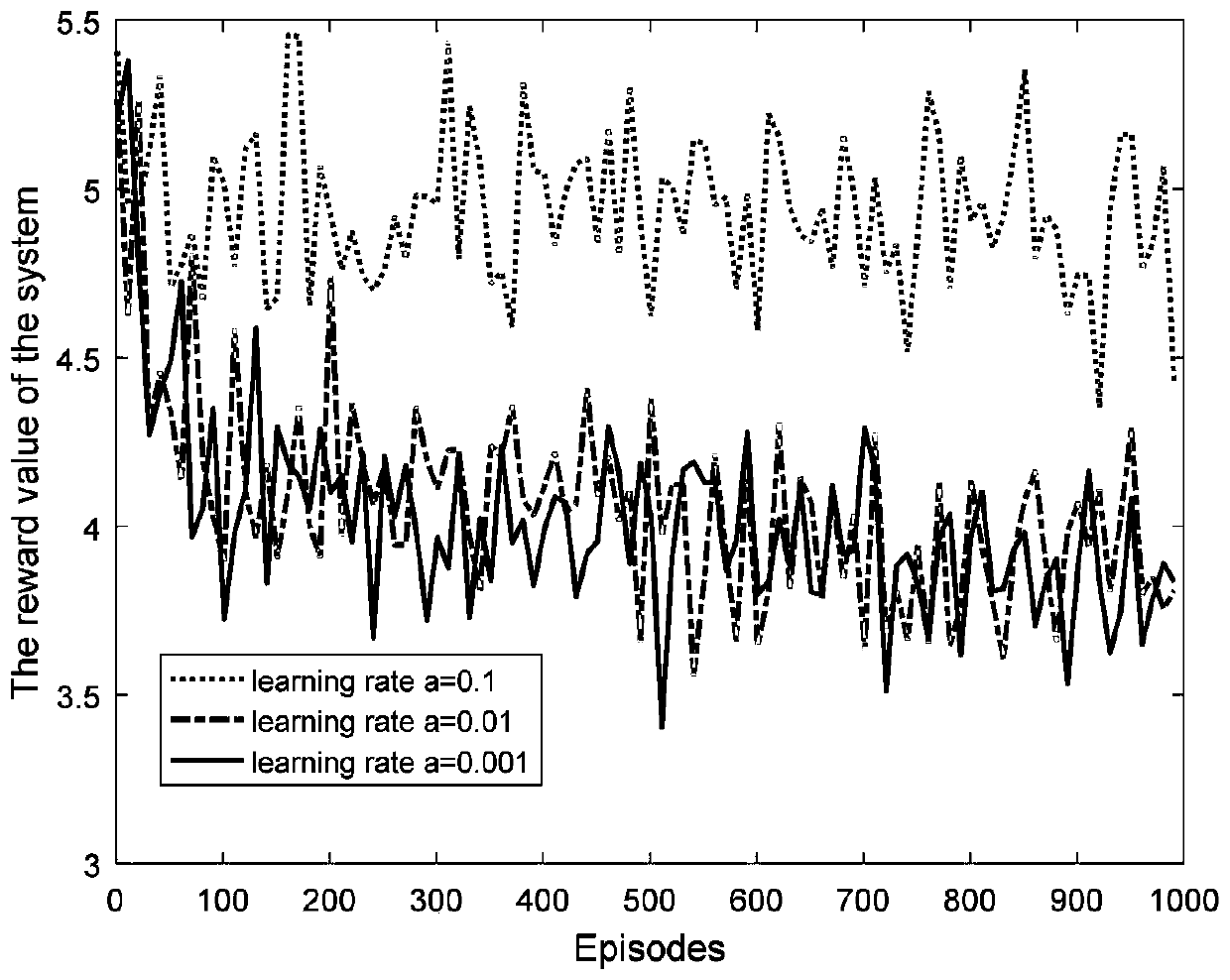
[0099] Such as figure 1 Shown is the convergence performance graph of the present invention based on the deep reinforcement learning algorithm at different learning rates. It can be seen from the graph that the reward value of the system gradually tends to a stable value as time increases. Under the same training environment, the smaller the learning rate, the better the network performance of the system. When the learning rate is 0.01...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More