

Medical record structured analysis method based on medical field entities
A structured and physical technology, applied in unstructured text data retrieval, special data processing applications, instruments, etc., to improve accuracy, avoid ambiguity, and improve recognition results
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
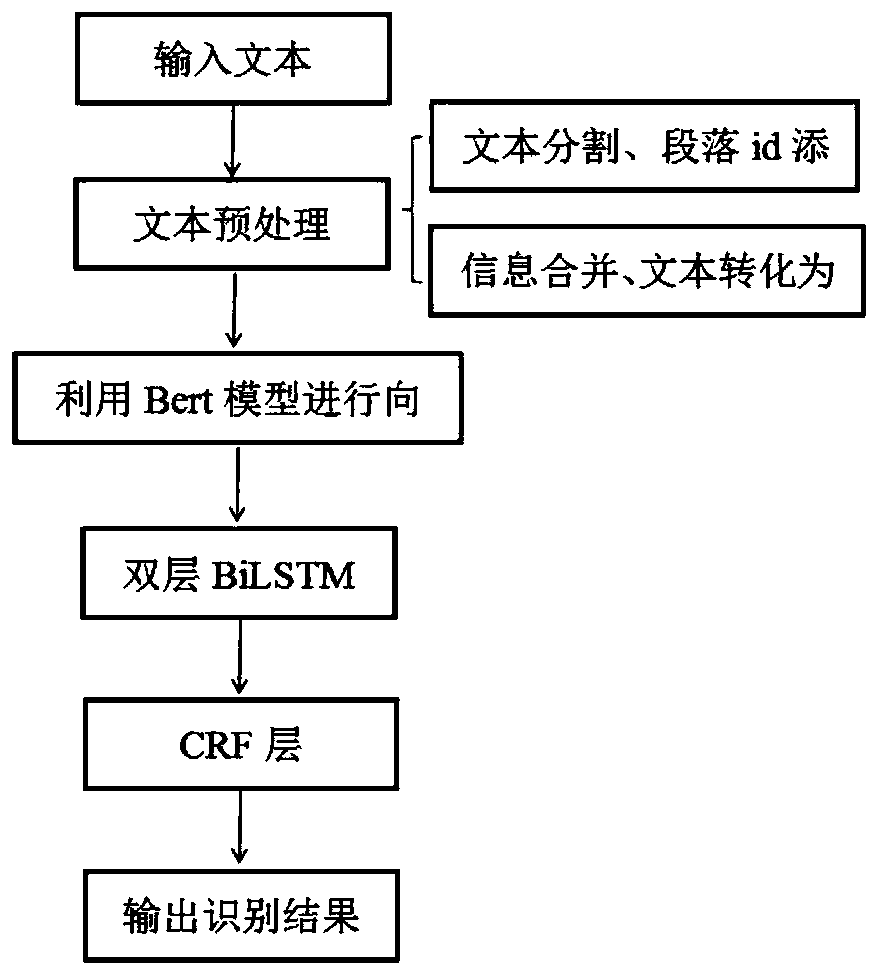
Method used
Image

Examples
Embodiment Construction
[0028] The present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments.
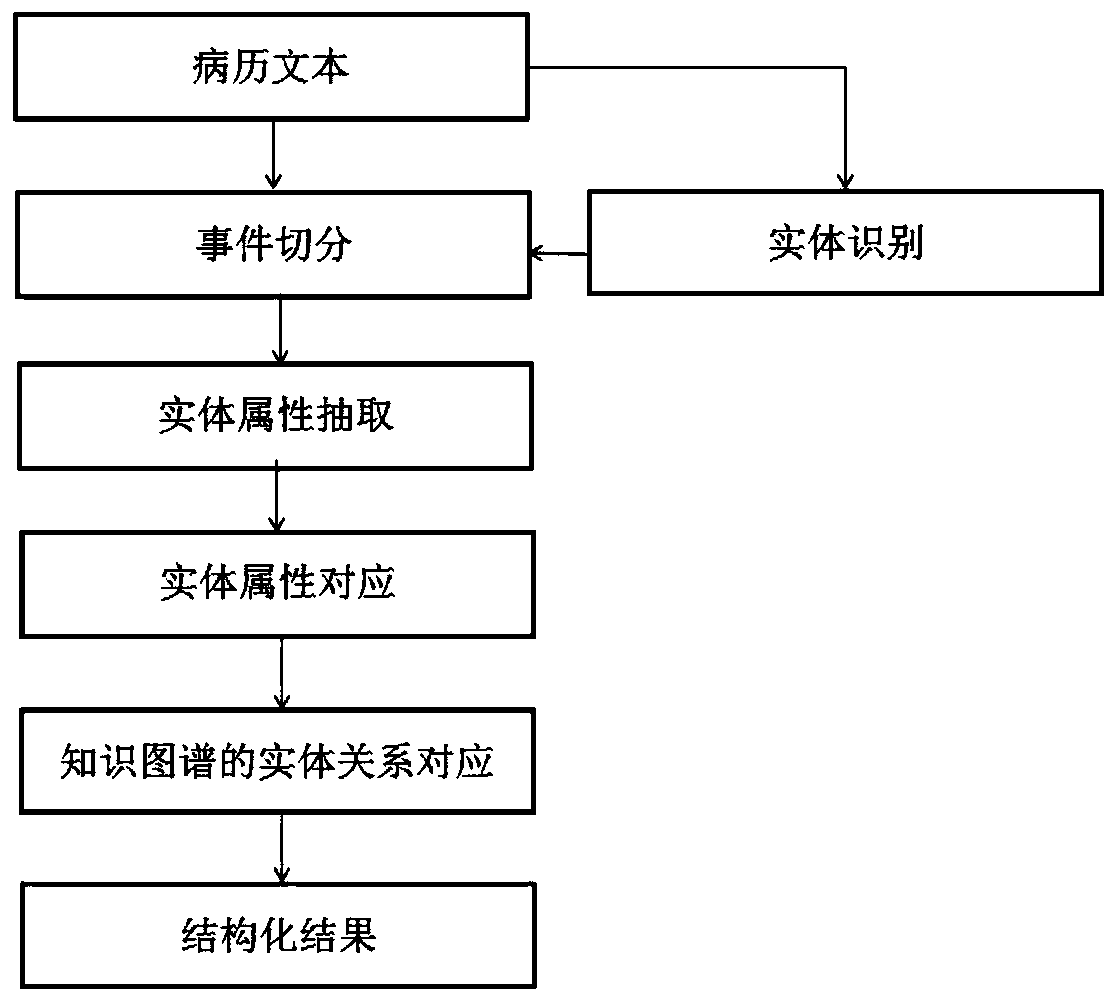
[0029] figure 1 It is a frame diagram of the overall implementation of a method for structural analysis of medical records based on entities in the medical field in this application. The method includes the following steps:
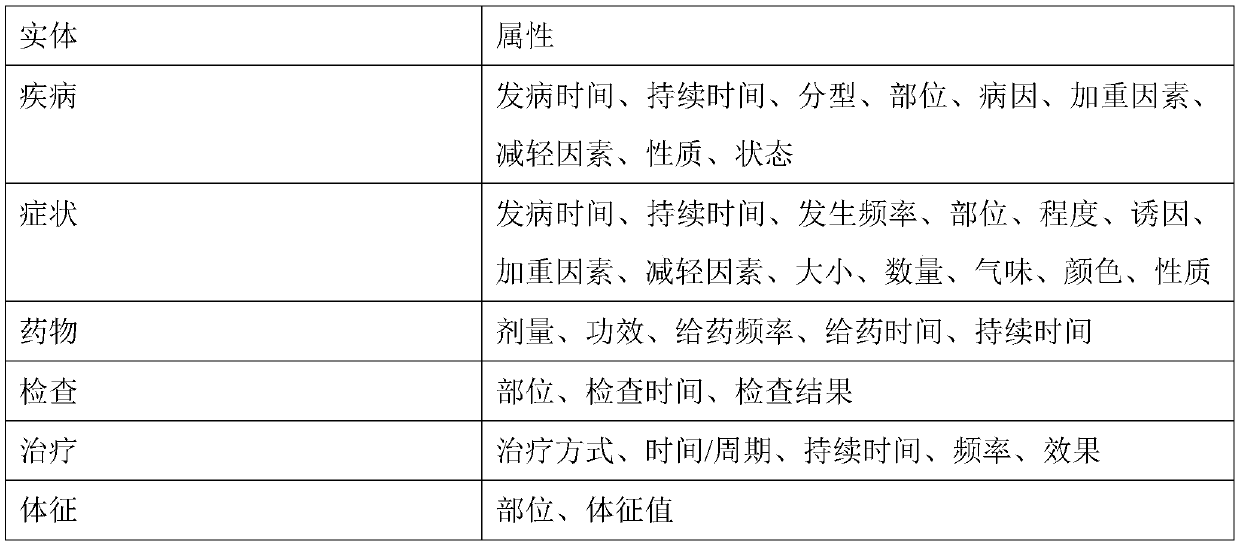
[0030] Step 1: Medical researchers select entities in the medical field. Entities in the medical field mainly include six categories: disease, symptom, drug, examination, sign, and treatment. Table 1 is the framework corresponding to the structured entity attributes of medical records defined in this application;
[0031] Table 1:
[0032]
[0033] Step 2: Create a mapping relationship table between entities and attributes; the attributes are also set by practitioners with medical experience in combination with business needs, mainly including: location, occurrence time, duration, frequency, size, quantity, degree, a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More