

Chinese text key information extraction method based on pre-trained language model
A language model and key information technology, applied in neural learning methods, biological neural network models, natural language data processing, etc., can solve problems such as the lack of boundary information of polysemous words, enrich semantic features, and solve the problem of polysemy. the effect of righteousness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0024] Below in conjunction with specific embodiment, further illustrate the present invention, should be understood that these embodiments are only used to illustrate the present invention and are not intended to limit the scope of the present invention, after having read the present invention, those skilled in the art will understand various equivalent forms of the present invention All modifications fall within the scope defined by the appended claims of the present application.
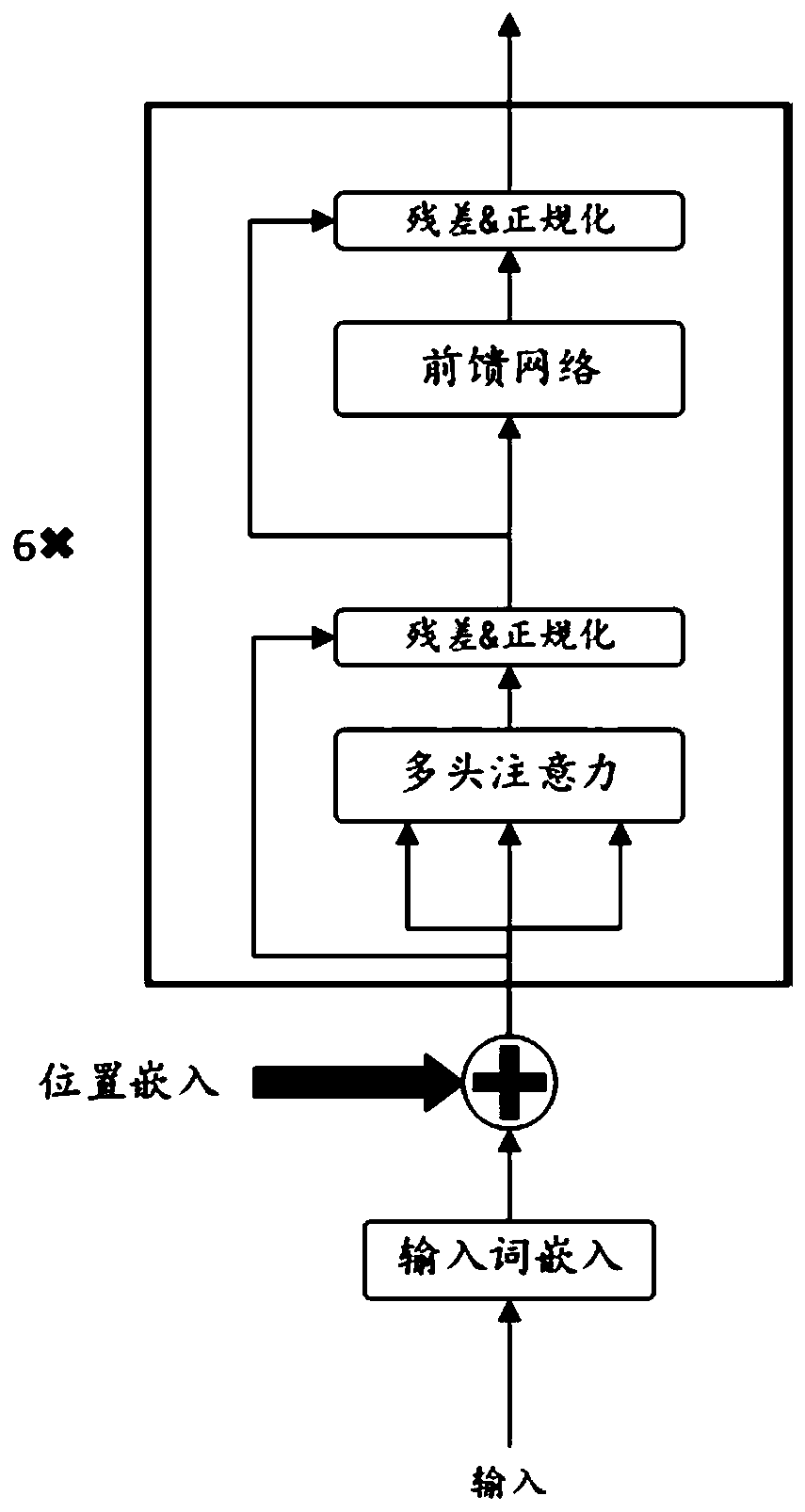
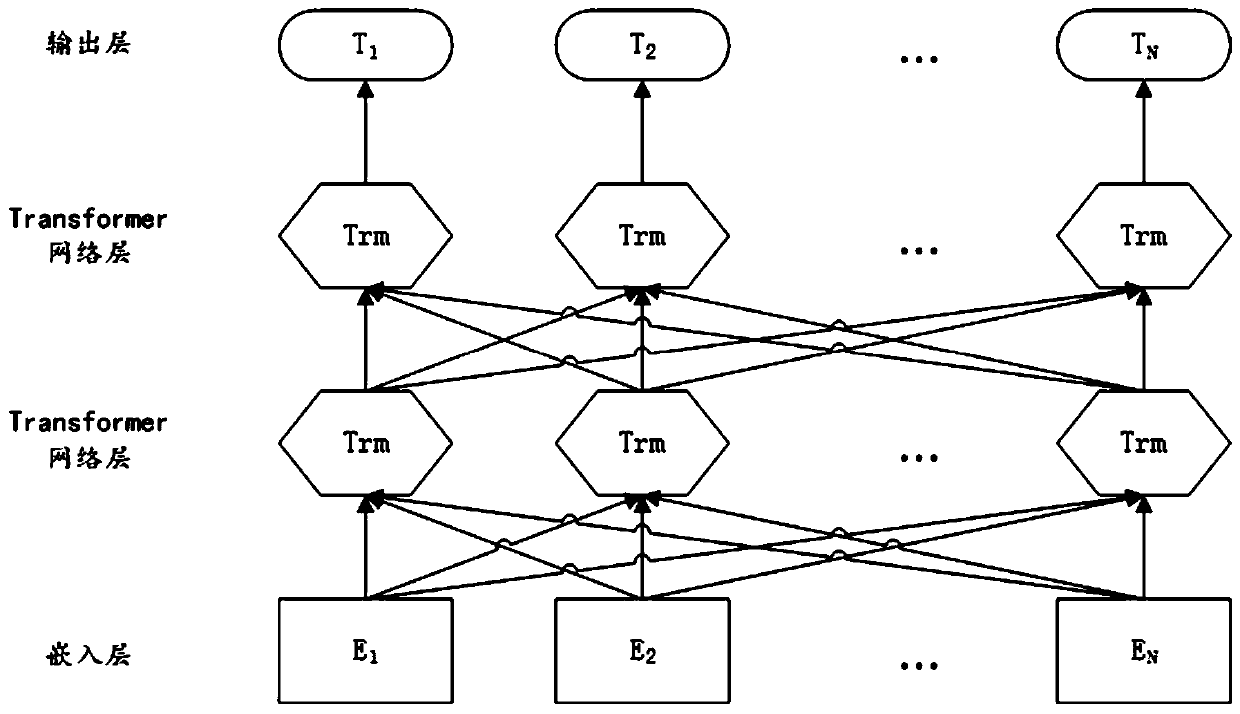
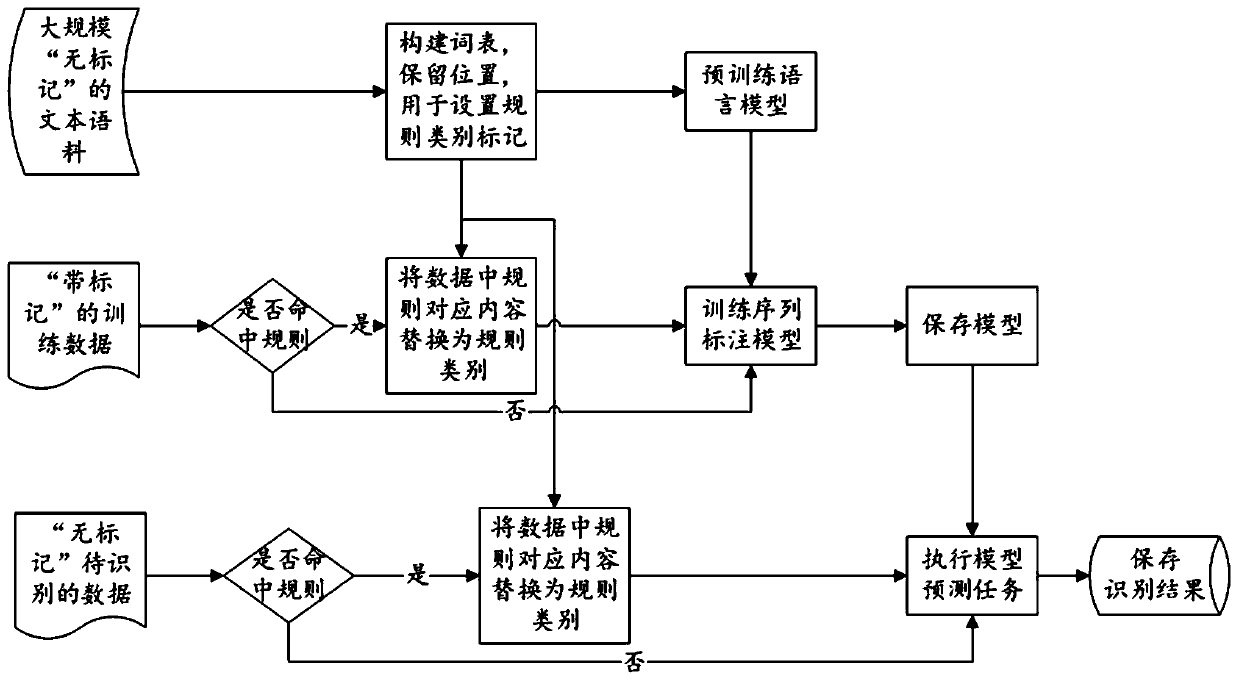
[0025] The present invention mainly aims at extracting key text information in complex scenes, and presents a method based on a pre-trained language model. This method divides the information category to be extracted into two modules: one is the module of using rule matching; the other is the module of named entity recognition based on the deep learning model. This method can deeply integrate regular matching features and deep language model semantic features, thereby improving recognition accurac...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More