

Voice conversion system, method and application
A technology for transforming systems and sounds, applied in speech analysis, speech recognition, instruments, etc., can solve problems such as inflexibility, sudden increase in computing volume, inappropriate computing resources and equipment, etc., to improve flexibility, shorten training time, alleviate The effect of inaccurate pronunciation
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0046] A sound transformation system,
[0047] include:
[0048] (1) The speaker-independent speech recognition (AI-ASR) model adopts a five-layer DNN structure, of which the fourth layer uses the Bottleneck layer to transform the Mel cepstrum feature (MFCC) of the source speech into the source speech bottleneck feature(Bottleneck Feature);
[0049] The ASR model converts speech into text, and the model outputs the probability of each word corresponding to the audio, and PPG is the carrier of this probability. The PPG-based method uses PPG as the output of the SI-ASR model.
[0050] PPG is Phonetic PosteriorGram, which is a matrix that maps each audio time frame to the posterior probability of a certain phoneme category. To a certain extent, PPG can represent the rhythm and prosody information of a speech content, and at the same time, it removes the features related to the speaker's timbre, so it is independent of the speaker. PPG is defined as follows:
[0051] P_t=(p(s...
Embodiment 2
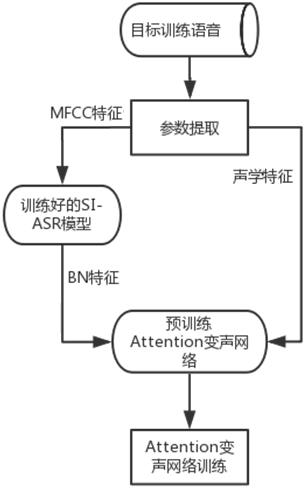
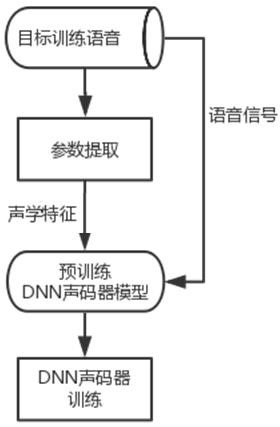
[0065] Introduce a sound transformation system training method, including the following three parts A1-A3:
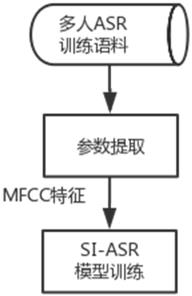
[0066] A1, SI-ASR model (speaker-independent speech recognition model) training phase. This stage is trained to obtain the SI-ASR model used in the training stage of the Attention voice-changing network (attention voice-changing network) and the extraction of Bottleneck features (literally translated as bottleneck features, also referred to as BN features) in the voice conversion stage; the training of this model includes The training corpus of many speakers is trained. After training, it can be used for any source speaker, that is, it is speaker-independent (Speaker-Independent, SI), so it is called the SI-ASR model; after training, it can be used directly later without repetition train.
[0067] The SI-ASR model (Speaker Independent Speech Recognition model) training phase consists of the following steps (see attached figure 1 ):
[0068] B1. Preprocessing the mul...
Embodiment 3
[0096] Embodiment 3, a sound transformation method.
[0097] Perform sound transformation on the input source speech, and transform it into a target speech signal output, that is, the speech conforms to the characteristics of the target speaker's voice, but the speech content is the same as the source speech.
[0098] The sound conversion phase consists of the following steps (see appendix Figure 4 ):
[0099] E1, the source speech to be converted is carried out parameter extraction, obtains MFCC characteristic;
[0100] E2, use the SI-ASR model trained in B3 to transform the MFCC feature into a BN feature;
[0101] E3. Use the Attention voice-changing network trained in C5 to transform the BN feature into an acoustic feature (mel spectrum);
[0102] E4. Use the neural network vocoder trained in D4 to convert the acoustic features (mel spectrum) into speech output.
[0103] In this way, the trained speaker-independent speech recognition model can be used for any source sp...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More