

Method and device for deploying multi-model inference service based on k8s cluster
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

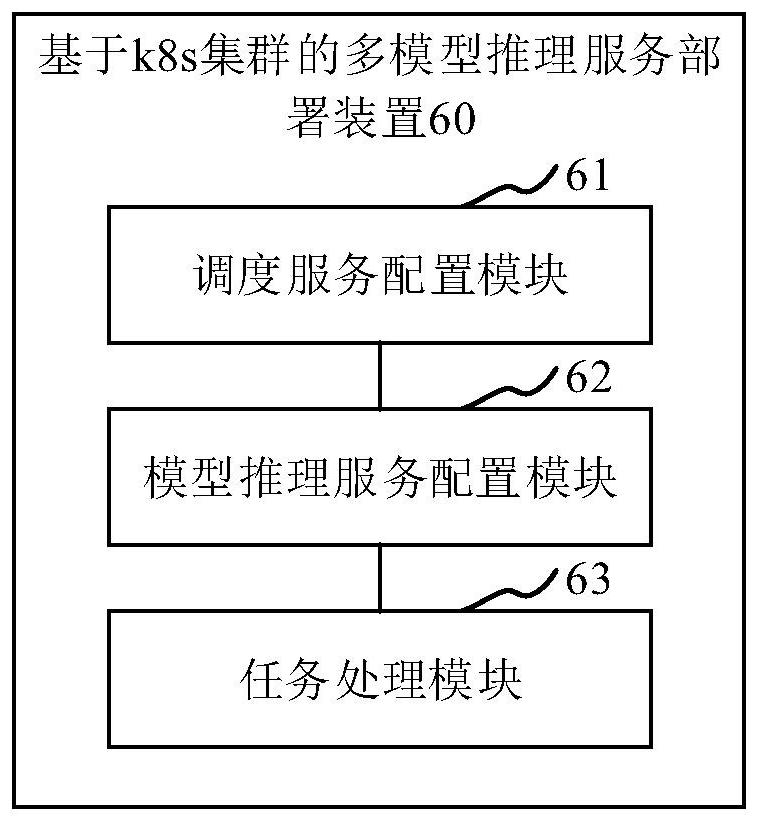
Examples
Embodiment Construction
[0038] It should be noted that all expressions using "first" and "second" in the embodiments of the present invention are for the purpose of distinguishing two entities with the same name but not the same or non-identical parameters. It can be seen that "first" and "second" It is only for the convenience of expression and should not be construed as a limitation to the embodiments of the present invention, and subsequent embodiments will not describe them one by one.
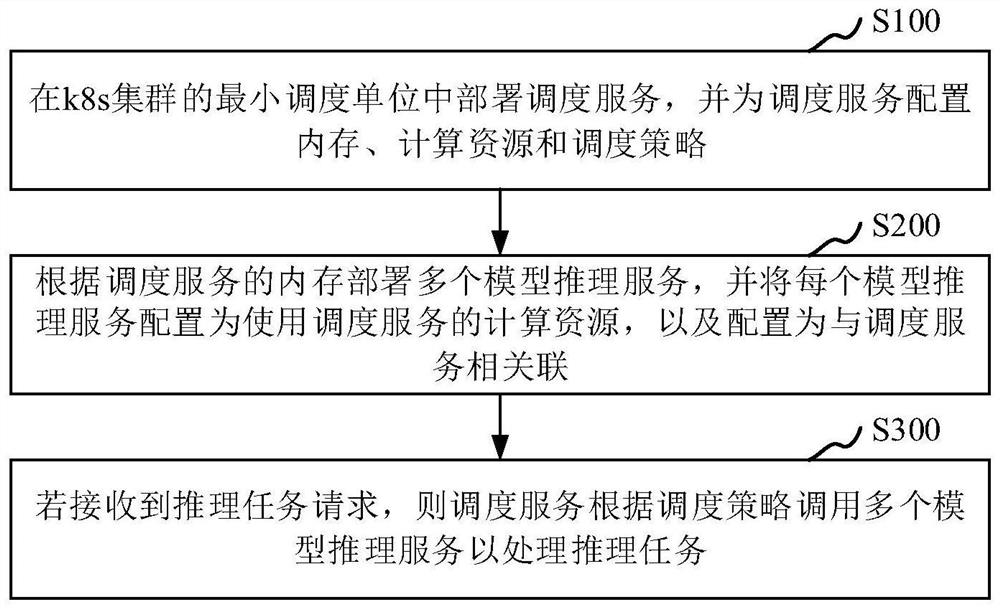
[0039] In one embodiment, please refer to figure 1 As shown, the present invention provides a multi-model inference service deployment method based on k8s cluster, and the method specifically includes the following steps:
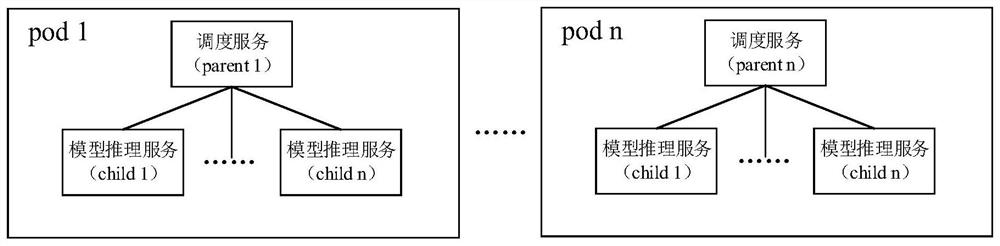
[0040] S100, deploying a scheduling service in the minimum scheduling unit of the k8s cluster, and configuring memory, computing resources and scheduling policies for the scheduling service; wherein, the minimum scheduling unit is a pod;
[0041] S200: Deploy a plurality of model inference se...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More