Search engine selection abstract generation method and device
A search engine and abstract technology, applied in the field of search engines, can solve problems such as inability to meet user needs, improve user experience and search quality, and take into account query costs and answer accuracy.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
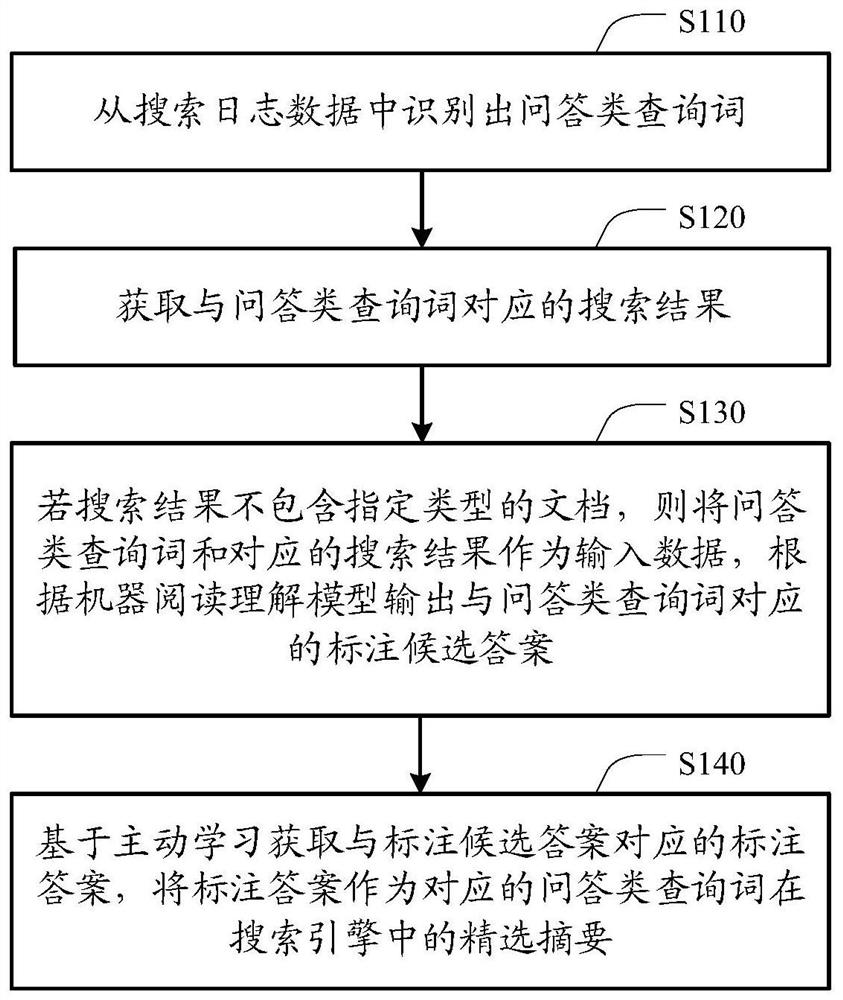
[0024] Exemplary embodiments of the present invention will be described in more detail below with reference to the accompanying drawings. Although exemplary embodiments of the present invention are shown in the drawings, it should be understood that the invention may be embodied in various forms and should not be limited to the embodiments set forth herein. Rather, these embodiments are provided for more thorough understanding of the present invention and to fully convey the scope of the present invention to those skilled in the art.
[0025] The design idea of the present invention is that, different from the traditional search results, a "selected abstract" is provided for question-and-answer query words, so that users can obtain more accurate results without clicking on the webpage to jump to the search result page. high answer. For example, a search engine can extract the definite answer to a user's question and put it in the first place in the returned results in a mor...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More