

High-resolution remote sensing image semantic segmentation method based on model depth integration
A remote sensing image and semantic segmentation technology, which is applied to biological neural network models, character and pattern recognition, instruments, etc., can solve the problems of unable to capture the scale features of ground objects, and the target scale span of remote sensing images is large, so as to reduce the training time and training time. The effect of increasing the difficulty and ensuring the accuracy of the model
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
[0066] In order to verify the effectiveness of the ED-FNet network architecture proposed in this chapter, in this example, experiments are carried out on the ISPRSVaihingen and ISPRS Potsdam datasets.
[0067] The Vaihingen dataset 5 consists of 33 aerial images collected in a 1.38km2 area of Vaihingen with a spatial resolution of 9cm. The average size of each image is 2494 × 2064 pixels, and each image has three bands corresponding to near infrared (NIR), red (R) and green (G) wavelengths. This dataset also specifically provides DSM also as supplementary data, which represents the surface height of all objects in the image. In these images, there are 16 manually annotated pixel-level labels, and each pixel is classified into one of 6 land cover classes. Eleven images in this data set are used for training, and the remaining five images (image id: 11, 15, 28, 30, 34) are used to test the model in this embodiment.
[0068]The Potsdam dataset consists of 38 high-resolution a...
Embodiment 2
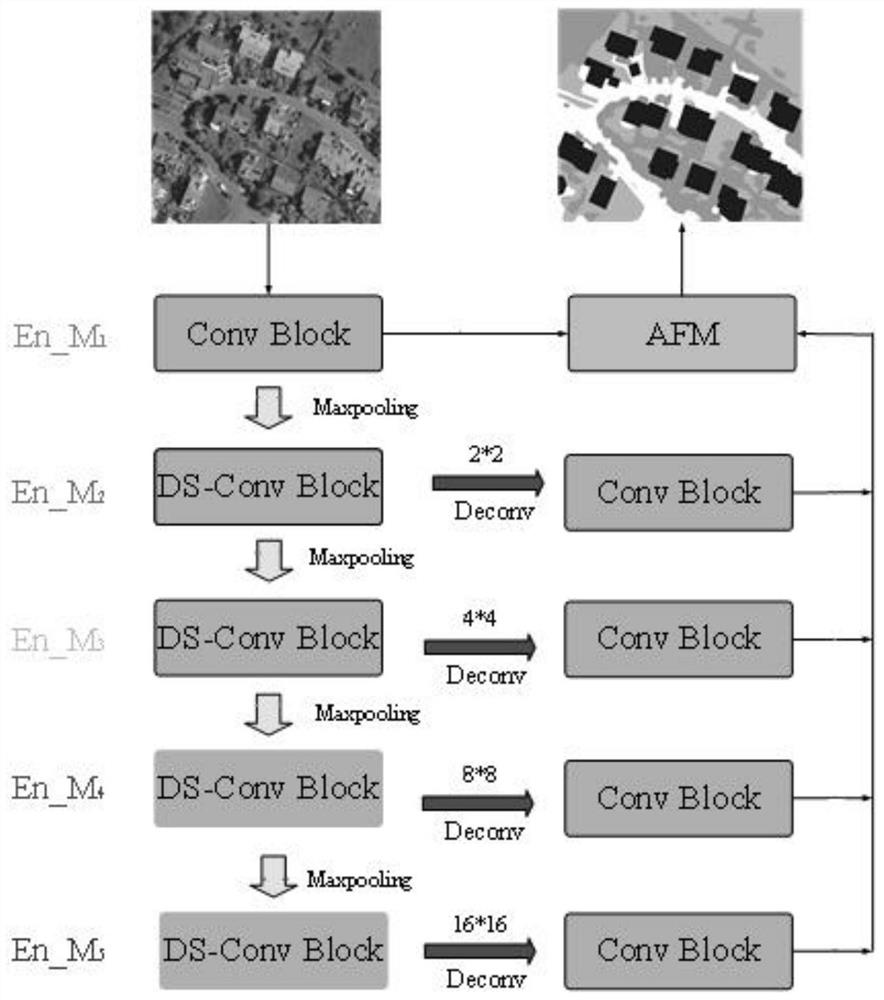
[0092] In this embodiment, an adaptive fusion module is proposed to solve the problem of how to fuse multiple output results of the model. In order to verify the effectiveness of the AMF module, an ablation experiment is designed, and the impact of the depth-separable convolution module on the model performance will also be tested. In this part of the experiment, U-Net is selected as the skeleton network structure, and AMF means adding an adaptive fusion module. In the last comparison model experiment, multiple loss constraints in DE_UNet were removed, and only the loss of the last layer of the network was retained to verify the importance of different depth models corresponding to loss constraints.
[0093] The experimental results are shown in Table 2. Compared with the original U-Net, the DE_UNet+AFM model proposed by the present invention improves OA / AF / mIoU by 1.23% / 1.8% / 2.5%. If the adaptive fusion module (AFM) is removed, the average weighted fusion method is used Over...
Embodiment 3
[0098]In order to further verify the effectiveness of the network in the present invention, an experiment was carried out on the Potsdam dataset. Compared with the Vaihingen dataset, the Potsdam dataset has a larger picture coverage and a higher pixel resolution of the picture. The Potsdam dataset in a single image has more local texture information and spatial multi-scale information, the background is more complex, and its segmentation is more difficult. The accuracy of the same model on the Potsdam dataset is often lower than that on the Vaihingen dataset. The specific numerical results are shown in Table 3. Table 3 shows the semantic segmentation results on the Potsdam dataset. The accuracy metric for each class is IoU. The best results for vgg and resnet at different depths are marked in gray.
[0099] It can be seen from the table that DE_UNet has increased by 1.13% / 0.87% / 1.25% on OA / mF1 / mIoU compared to U-Net, and DE_PNet has increased by 1.06% / 0.9% / 0.9% on OA / mF1 / mIo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More