

Learning text hashing method based on autoencoder
A self-encoder and learning-based technology, applied in the field of computer information processing, can solve the problems of high collision rate and long hashing time of traditional hash functions, achieve low hash collision rate, improve computing time, and improve efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

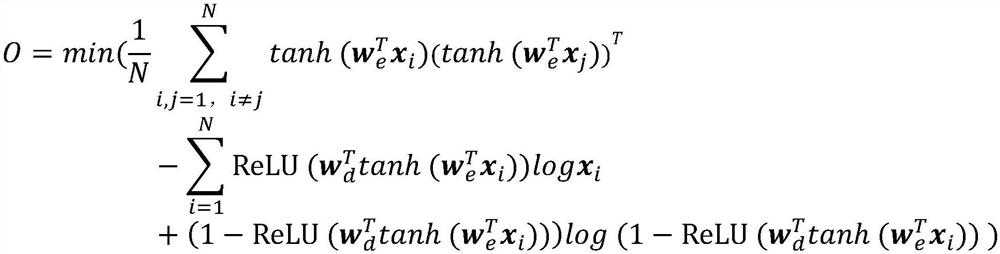
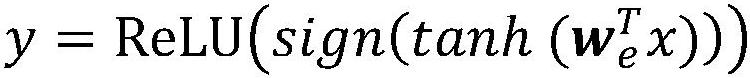
Examples
Embodiment Construction
[0018] In order to make the objectives, technical solutions and advantages of the present invention clearer, the present invention will be further described in detail below with reference to specific examples.
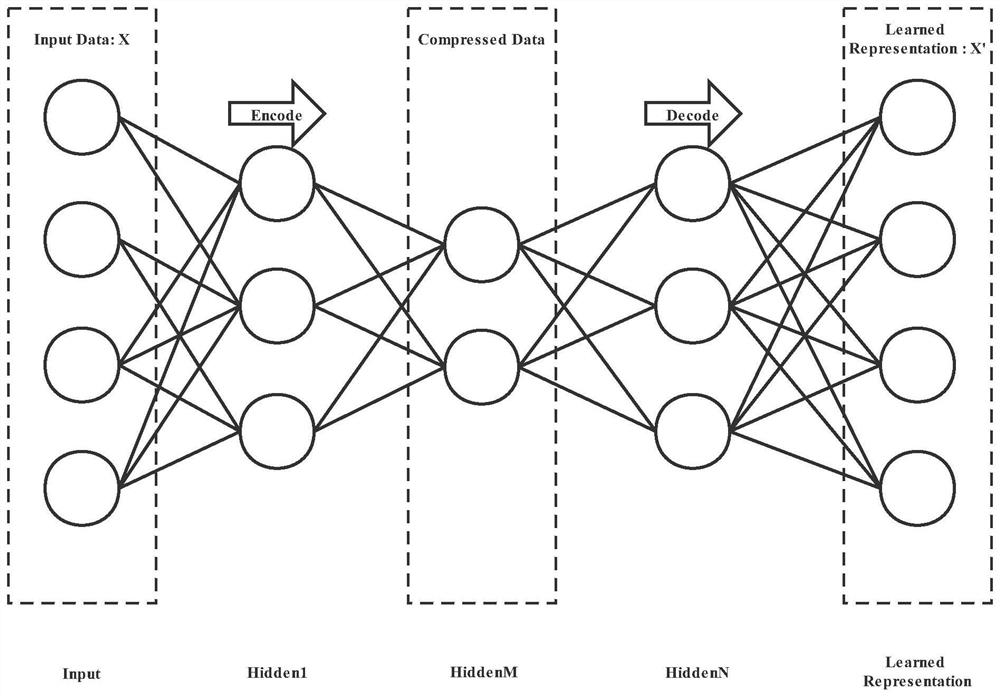
[0019] The learning text hashing method based on autoencoder includes the following steps:
[0020] Step 1. Construct a training data set using real collected text data and / or program-generated text data.
[0021] The process of the text data generated by the program is: first, you need to obtain the number of characters L of the text to be generated, and the number of records N, and specify the path of the file saved in the file. The number of characters is fixed at 128, and the save path is train.txt, then L is 128 and N is 1000. After obtaining the above parameters, prepare a text set, and generate N pieces of text data one by one in a loop. When the N pieces of data are generated, jump out of the loop and save the text data in the text set to the specified path. ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More