Search result generation method and device
A technology for search results and search information, applied in the field of search result generation methods and devices, capable of solving problems such as unsupported provision, dedicated system does not support the provision of candidate contacts, and users cannot find solutions smoothly, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


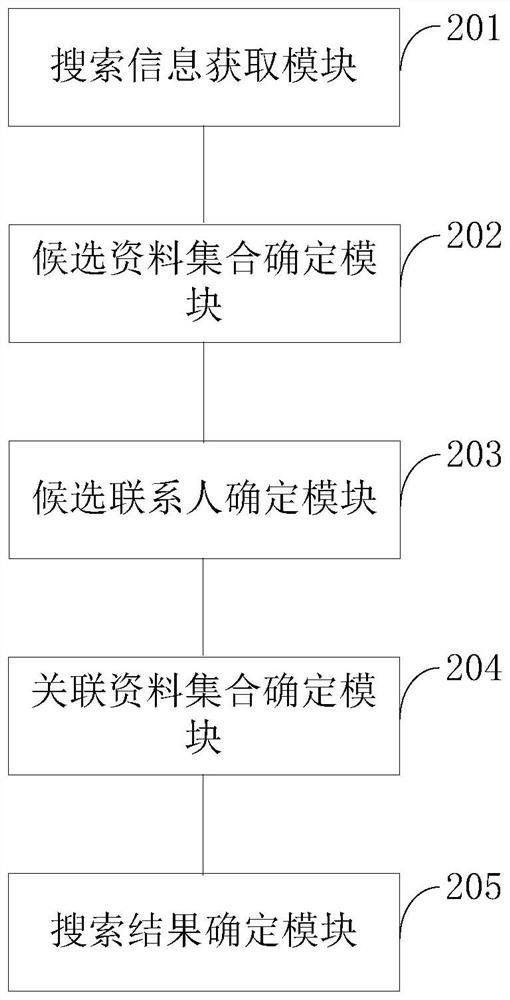
Examples
Embodiment Construction
[0050] The technical solutions in the embodiments of the present application will be clearly and completely described below with reference to the drawings in the embodiments of the present application. Obviously, the described embodiments are only a part of the embodiments of the present application, but not all of the embodiments. Based on the embodiments in the present application, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present application.
[0051] In view of the problems existing in the prior art, the inventor of the present application has conducted in-depth research and finally proposed a method for generating search results. Next, the method for generating search results provided by the present application will be described in detail through the following embodiments.
[0052] see figure 1 , showing a schematic flowchart of the method for generating search results provid...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More