

Webpage mark extracting method
A webpage identification and storage structure technology, applied in the field of search engines, can solve the problems of occupation, more memory, and time-consuming processing, and achieve the effects of reducing excessive occupation, increasing processing speed, and reducing the number
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
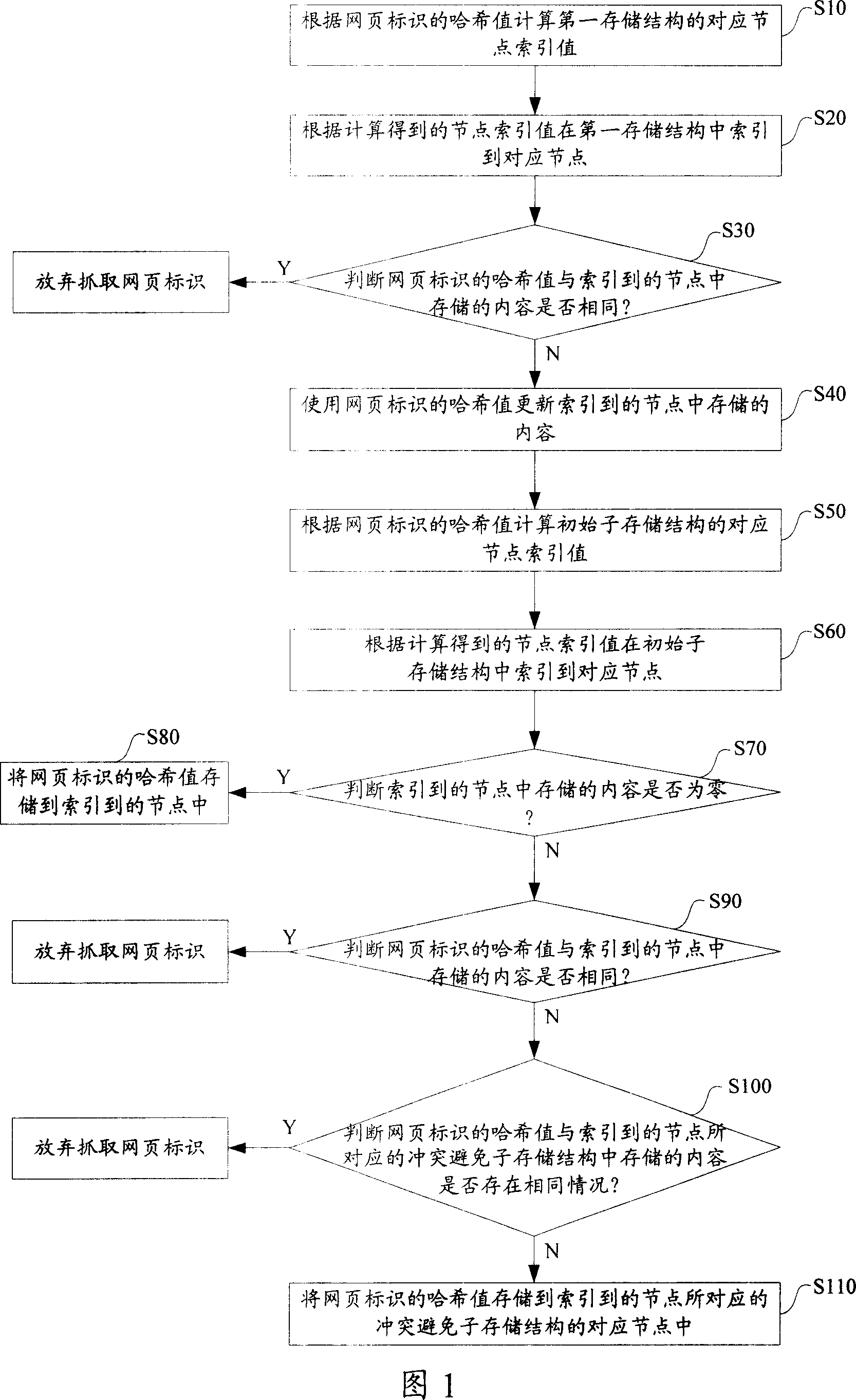
[0049] The main realization principle, specific implementation process and beneficial effects of the present invention will be described in detail below with reference to each accompanying drawing.
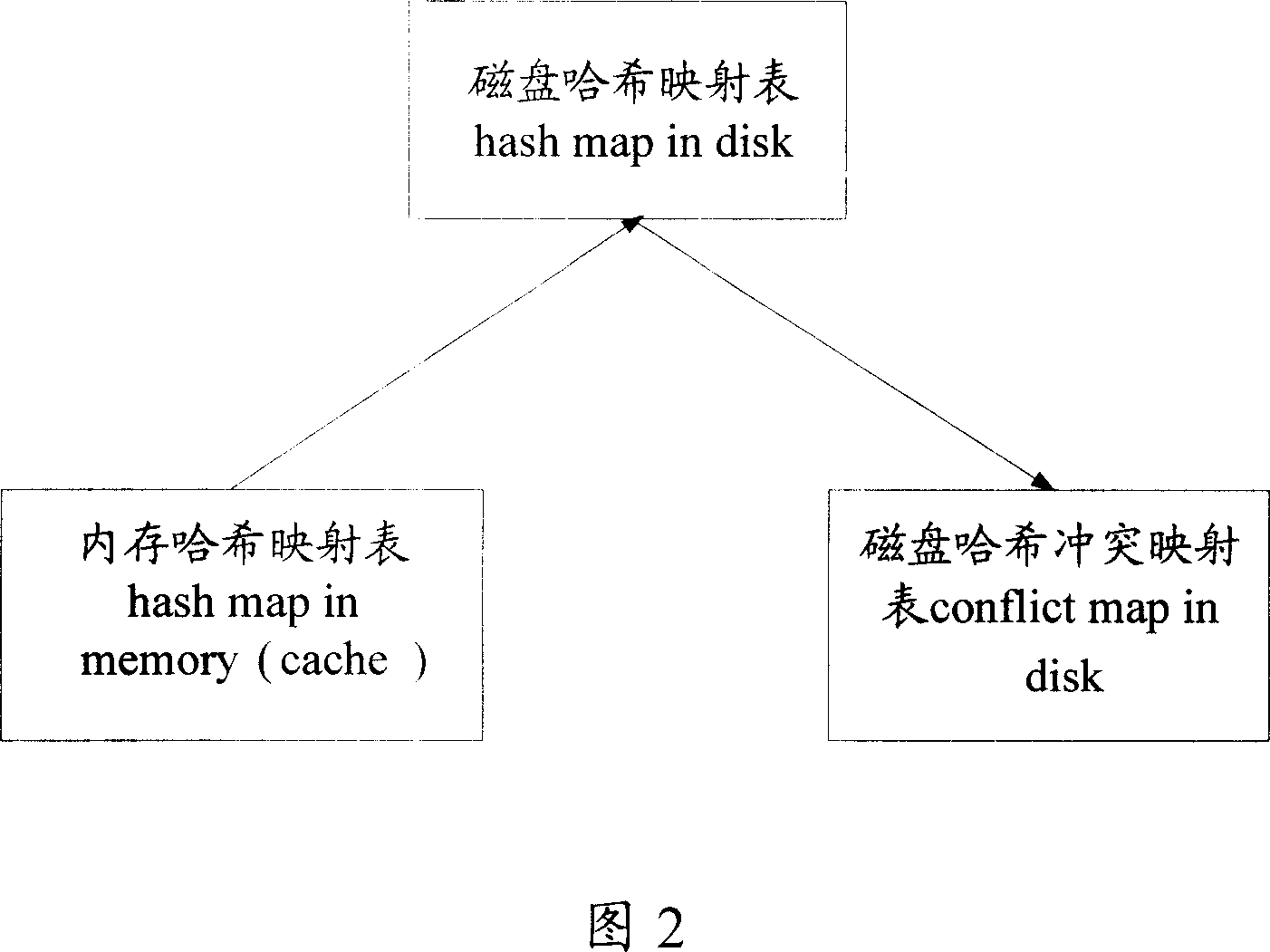
[0050] Please refer to Fig. 1, which is a flow chart of the main realization principle of the method for grabbing webpage identifiers of the present invention, wherein in the realization process of the method of the present invention, at least one first storage structure needs to be set in advance to store a specified number of the most recent Preferably, the hash value of the captured web page identification is required to set the first storage structure of this setting in a storage medium with a higher processing speed and a higher price, such as a storage medium such as a memory; at the same time, it is necessary to set at least one The second storage structure is used to store all the hash values of webpage identifications that have been crawled, wherein the set second storag...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More