

Method for extracting content of text based on HTML characteristics
An extraction method, a technology of HTML web pages, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve the problems of mixing, increasing the accuracy of text clustering and text classification, and extracting more content, etc., to achieve Reduced workload, reduced system consumption, and improved analysis efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
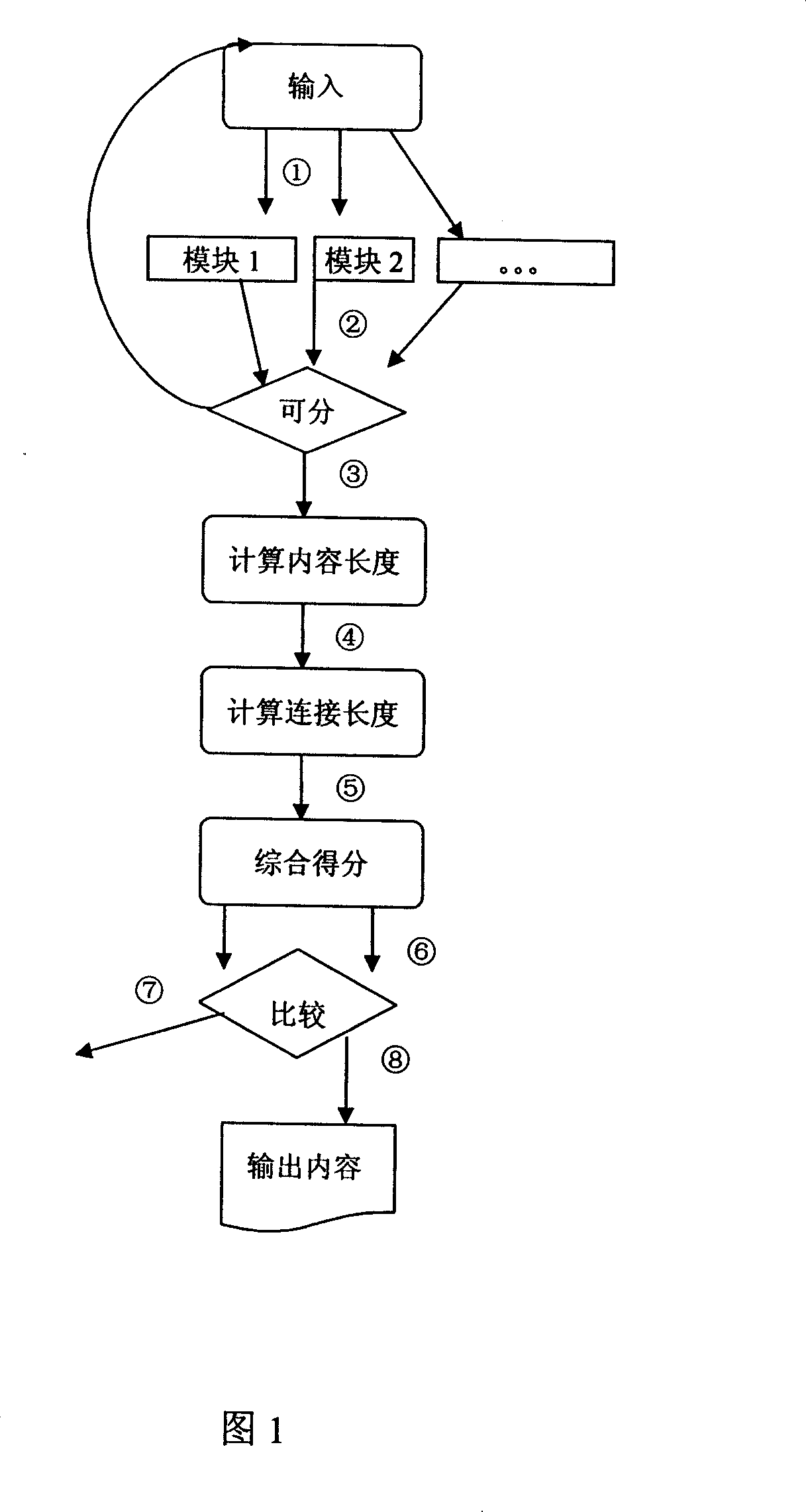
[0017] The present invention will be further described below in conjunction with accompanying drawing.
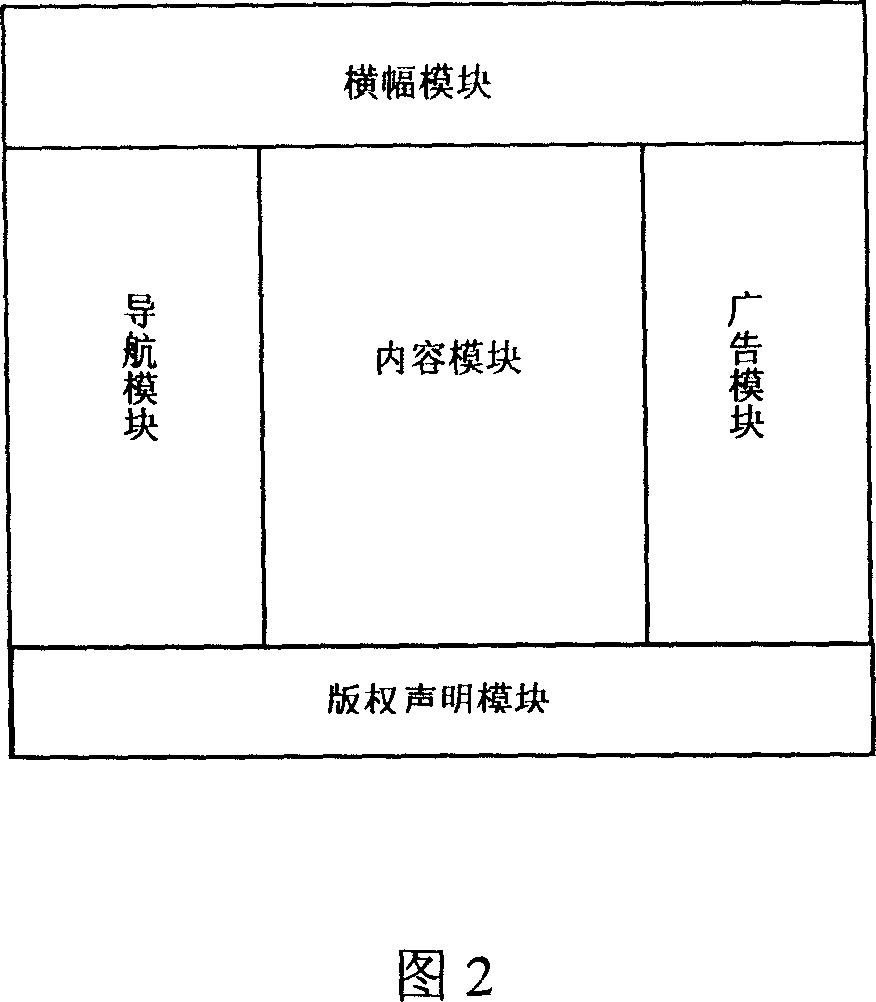
[0018] As shown in Figure 1, the HTML feature-based text content extraction method divides the web page layout into content modules and non-content modules. The content module is the content part of the webpage, and the non-content module is generally used to display information such as navigation information, banners, copyright notices or advertisements. The goal of the solution of the present invention is to decompose the HTML webpage and extract the content modules from the HTML webpage. For each decomposed module, we give different scores according to its position in the web page layout. The higher the score of the module that is in the focus of the user's sight, the lower the score. is too large, the module may display advertisements or navigation information. In the present invention, a module content comprehensive score formula is provided: comprehensive score=posi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More