

Method and system for extracting webpage information
A web page information and page technology, applied in the network field, can solve the problems of invalid positioning information, simple positioning information, and inability to solve repetitive structure identification well
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
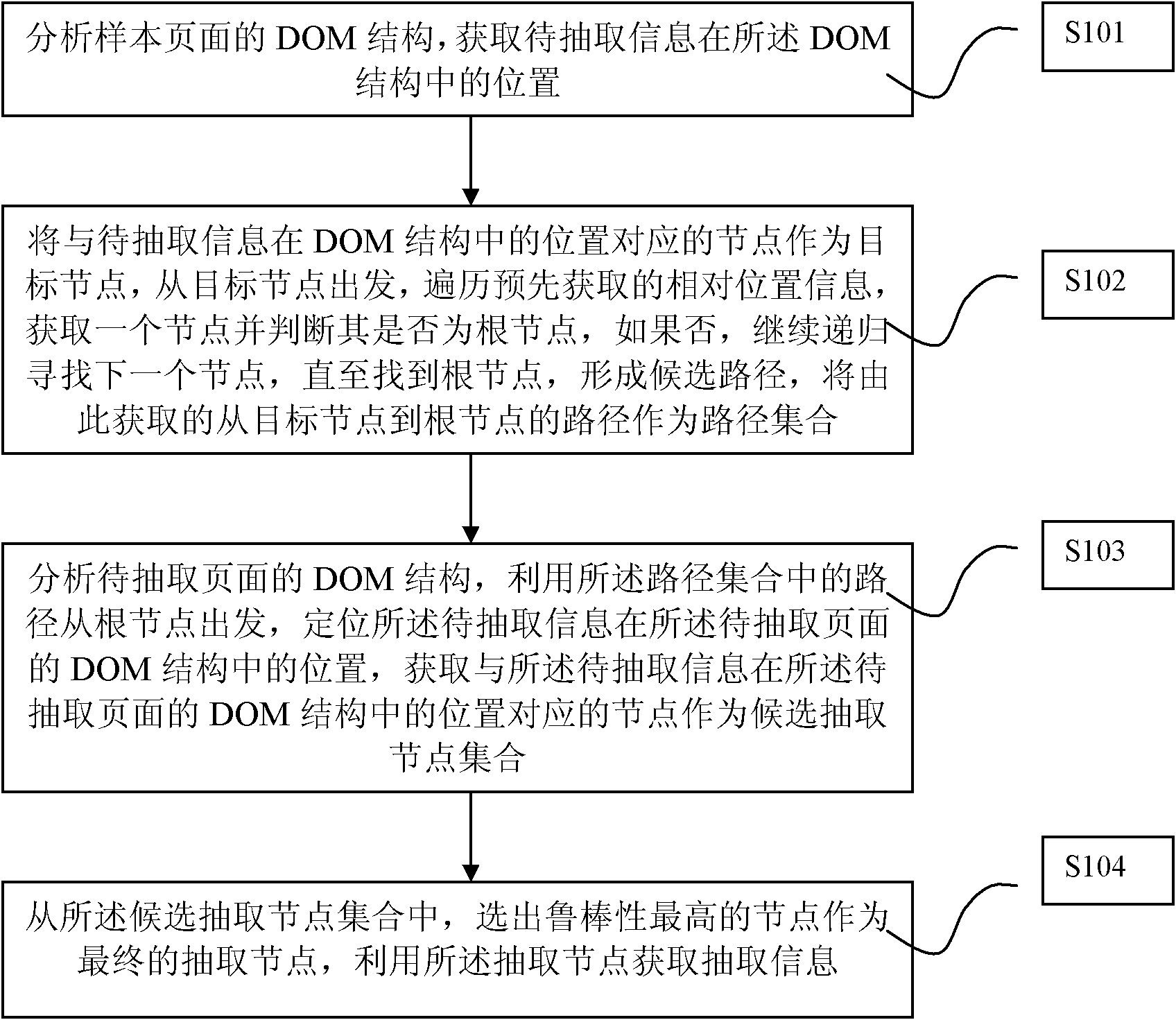
[0095] In the technical solution provided by this application, we first need to obtain the location information of the information to be extracted in the sample page, that is, the location information of the target node, so as to use the location information of the target node to obtain multiple paths from the target node to the root node. Here is the reverse positioning method. The sample page is generally provided by the user and is a web page that uses the same page template as the page to be extracted. One possible implementation is that the user inputs the web page address according to the information that needs to be extracted, and downloads the web page as a sample page. The sample pages may be downloaded from different sites. At this time, correspondingly, the page to be extracted is a collection of web pages with the same page template corresponding to the sample pages. Of course, the sample page can also be obtained in other ways, and this application does not restri...
Embodiment 2
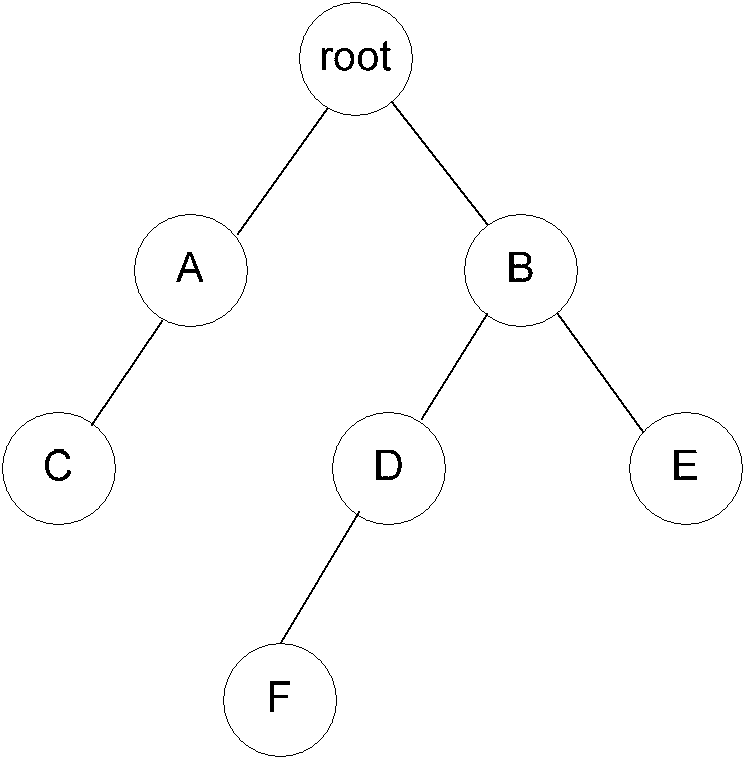
[0192] In a preferred embodiment of the present application, when obtaining all paths from the target node to the root node as a path set, the reliability judgment rule is used to find the first N paths from the target node to the root node with the least deductions. The path is a collection of paths. Among them, the higher the robustness, the fewer points will be deducted. In this way, the obtained path is no longer all paths from the target node to the root node, but the path with the least deduction as the path in the path set.
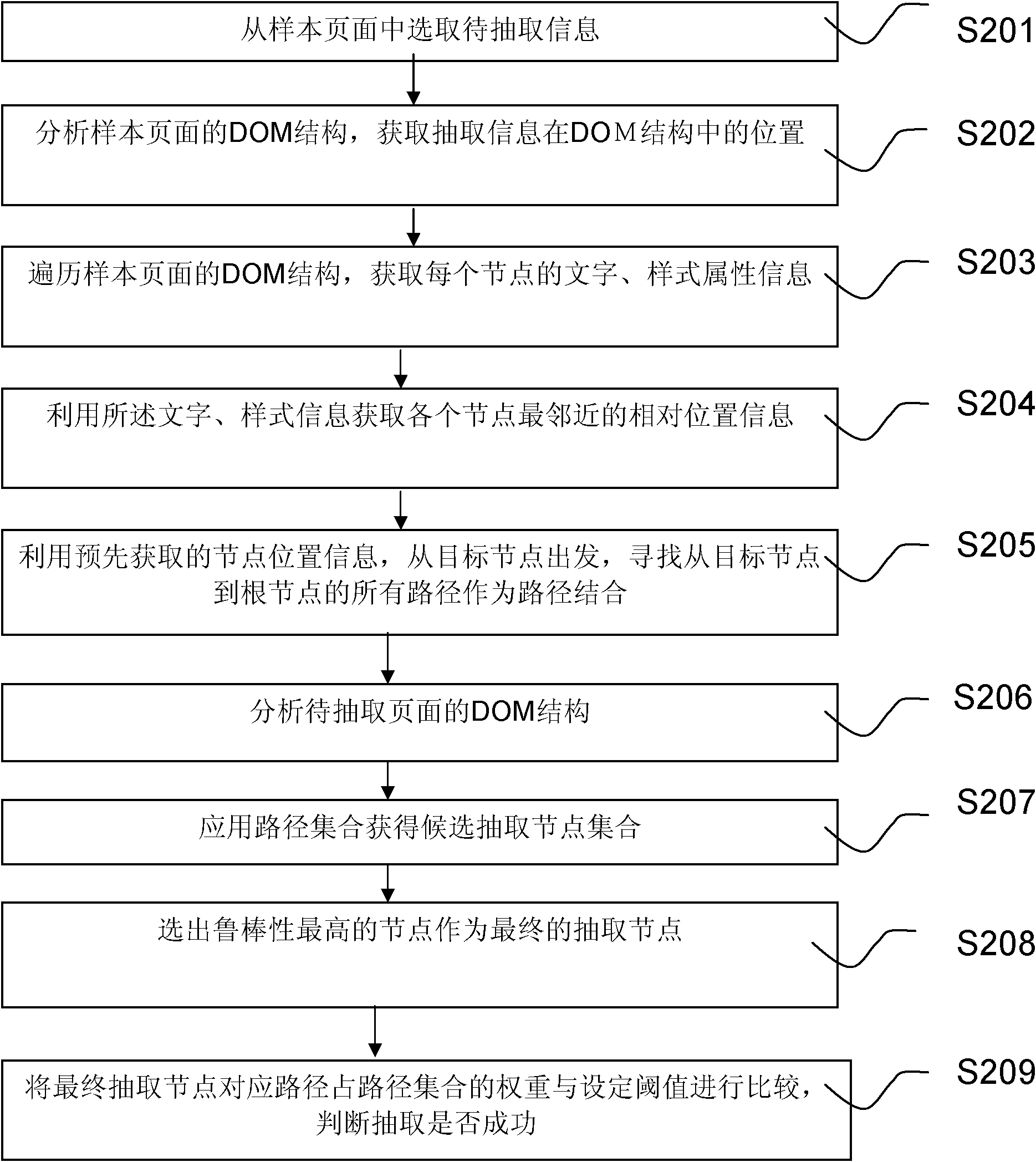
[0193] The second embodiment of the present application will be described below in conjunction with the drawings. Image 6 This is a schematic diagram of the method in Embodiment 2 of this application.
[0194] S601: Select information to be extracted from a sample page.
[0195] S602: Analyze the DOM structure of the sample page, construct a DOM tree, and obtain the position of the information to be extracted in the DOM structure.
[0196] S603: Travers...
Embodiment 3
[0228] In another preferred embodiment of the present application, the reliability judgment rule is also used to find the path from the target to the root node with the least deduction as the path set. The main difference between the third embodiment and the second embodiment is that the third embodiment finds all the paths from the target node to the root node, and then deducts points for all the paths found according to the reliability judgment rules, so as to select the top N with the least deduction. Paths. The second embodiment is in the process of spreading, that is, calculating the deduction of the path according to the reliability judgment rule. If the deduction exceeds the threshold value, the spreading is stopped.
[0229] Figure 8 It is a schematic flow diagram of the method of the third embodiment of the present application, which is described below with reference to the drawings.
[0230] S801: Select information to be extracted from a sample page.
[0231] In the emb...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More