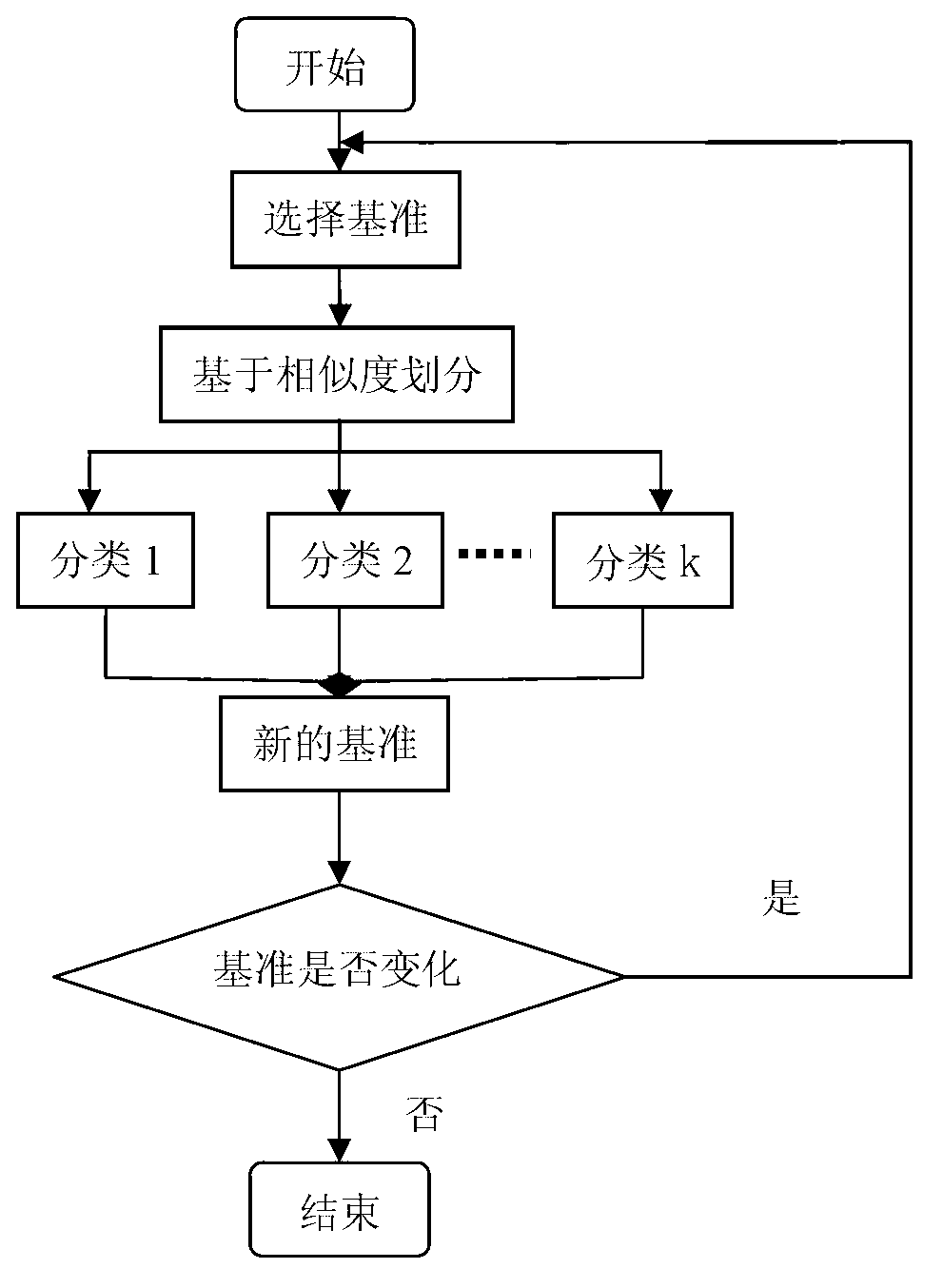
Association rule mining method of large-scale data
What is AI technical title?
AI technical title is built by Patsnap AI team. It summarizes the technical point description of the patent document.
A large-scale data and rule technology, applied in the field of distributed computing and data mining, can solve the problems of long data mining operation time, etc., and achieve the effects of improving mining efficiency, improving processing efficiency, and good scalability
Inactive Publication Date: 2013-04-03
UNIV OF ELECTRONICS SCI & TECH OF CHINA
View PDF2 Cites 37 Cited by
Summary
Abstract
Description
Claims
Application Information
AI Technical Summary
This helps you quickly interpret patents by identifying the three key elements:
Problems solved by technology
Method used
Benefits of technology
Problems solved by technology
A large number of candidate item sets will be generated during the implementation of the Apriori algorithm, resulting in long data mining operations, which is a major shortcoming based on the Apriori algorithm.
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View more
Image
Smart Image Click on the blue labels to locate them in the text.
Viewing Examples
Smart Image
Click on the blue label to locate the original text in one second.
Reading with bidirectional positioning of images and text.
Smart Image
Examples
Experimental program
Comparison scheme
Effect test
example 1
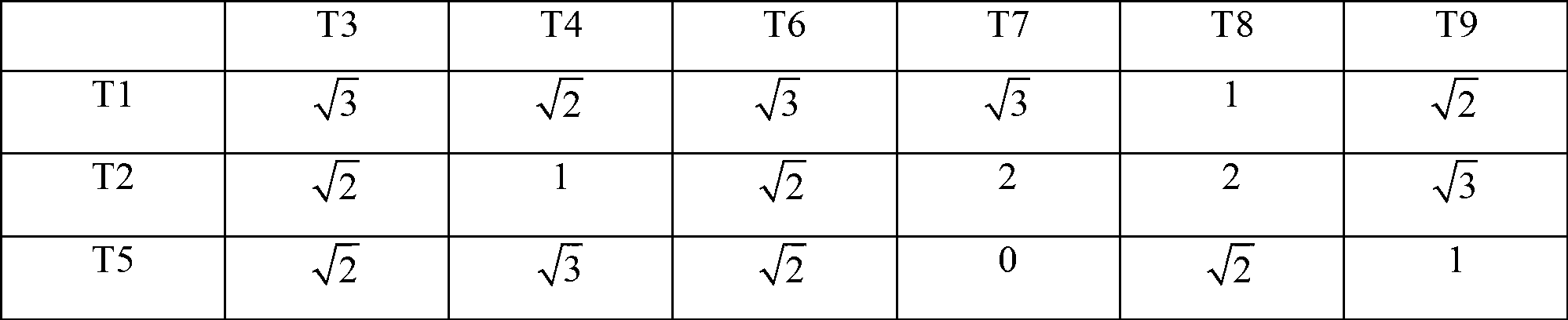
[0030] The input data table shown in Table 1 has 9 records (T1, T2, ..., T9) and the items contained in each record (I1, I2, I3, I4, I5):
[0033] In order to facilitate the calculation of the similarity between items in the data, the input data table is converted into a 0,1 state table, as shown in Table 2, 0 means that the current item does not appear in the corresponding record, and 1 means that the current item appears in the corresponding record middle:
[0034] Table 20,1 State table
[0035]
I1
I2
I3
I4
I5
T1
1
1
0
0
1
T2
0
1
0
1
0
T3
0
1
1
0
0
T4
1
1
...
example 2
[0069] Taking frequent itemset mining for a category (T2, T8) as an example, the default minimum support is 0.22.
[0070] The 0,1 state tables of records T2 and T8 are shown in Table 5:
[0071] Table 5 state table
[0072]
I1
I2
I3
I4
I5
T2
1
1
0
0
1
[0073] T8
0
1
0
1
0
[0074] In the first scan, the items contained in this category (I1, I2, I4, I5) are used as candidate item sets alone, and the corresponding support is greater than the minimum support of 0.22 as shown in Table 6:
[0075] Table 6 Support degree of the first scan
[0076]
Support
I1
50%
I2
1
I4
50%
I5
50%
[0077] The frequent 1-itemsets generated by the first scan are: I1, I2, I4, I5
[0078] In the second scan, 2 candidate item sets (I1, I2, I1, I4, I1, I5, I2, I4, I2, I5, I4, I5) including frequent 1-itemsets are generated, and the ...
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
PUM
Login to View More
Abstract
The invention provides an association rule mining method of large-scale data, and the method comprises the following steps that (1) the input data is subjected to classified preprocessing based on similarity, so that records in the same category have high similarity; (2) the data in each category is mined based on Apriori algorithm to obtain frequent item sets of all categories; and (3) the frequent item sets of all the categories are merged, and association rules which correspond to the frequent item sets which are more than the minimum confidence coefficient are determined to be strong association rules. According to the association rule mining method of large-scale data, unnecessary candidate item sets with small association can be reduced, so that the association rule mining efficiency of all the data is improved, and better expandability is realized.
Description
technical field [0001] The invention relates to distributed computing and data mining technology. Background technique [0002] Research on massive data management is not a new topic, but the definition of "massive" is constantly changing with the rapid development of storage devices. [0003] For large-scale data, the databasemanagement system indexes the data through Hash, B+'Iree and other means, which can effectively reduce the cost of reading and writing external memory and improve the efficiency of data query. In order to process a larger amount of data, Parallel DatabaseSystem (Parallel DatabaseSystem, referred to as PDBS) and Distributed DatabaseSystem (Distributed Database System, referred to as DDBS) have emerged one after another, connecting multiple data processing nodes into a whole through network connections, thus completing The task of efficiently processing massive amounts of data. [0004] Association rules were proposed by Agrawal et al. in the liter...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
Application Information
Patent Timeline
Application Date:The date an application was filed.
Publication Date:The date a patent or application was officially published.
First Publication Date:The earliest publication date of a patent with the same application number.
Issue Date:Publication date of the patent grant document.
PCT Entry Date:The Entry date of PCT National Phase.
Estimated Expiry Date:The statutory expiry date of a patent right according to the Patent Law, and it is the longest term of protection that the patent right can achieve without the termination of the patent right due to other reasons(Term extension factor has been taken into account ).
Invalid Date:Actual expiry date is based on effective date or publication date of legal transaction data of invalid patent.



 Login to View More
Login to View More  Login to View More
Login to View More