Set characteristic vector-based quick clustering method and device
A technology of eigenvectors and clustering methods, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve the problems of large differences in the size of clustering results, the impact of clustering results, and large differences in clustering results, etc. , to achieve the effects of rich data types, high clustering stability, and high clustering efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
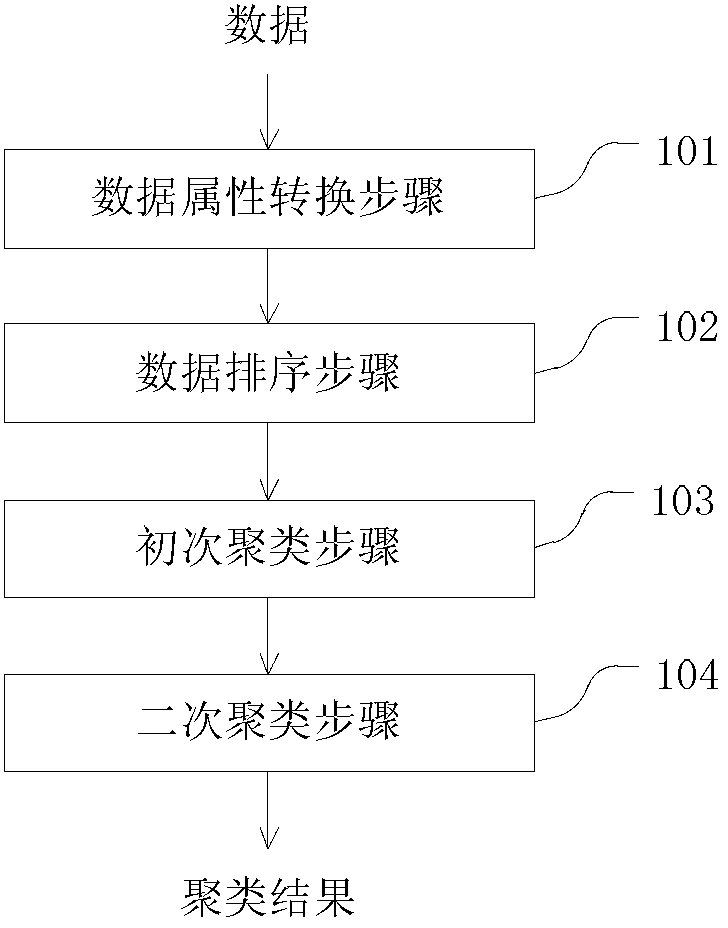
[0042] Embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings. First, a fast clustering method based on set feature vectors according to an embodiment of the present invention will be described.
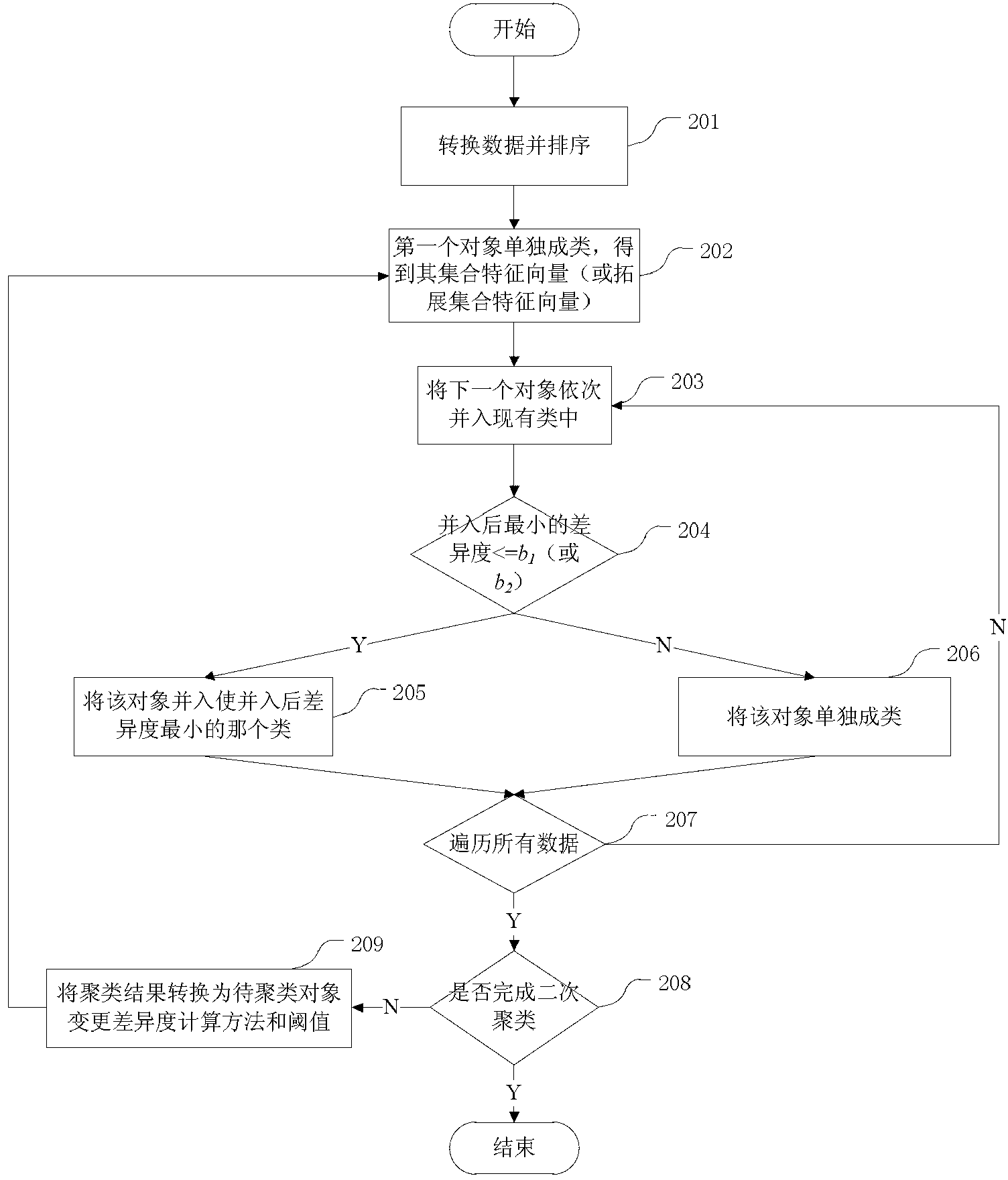
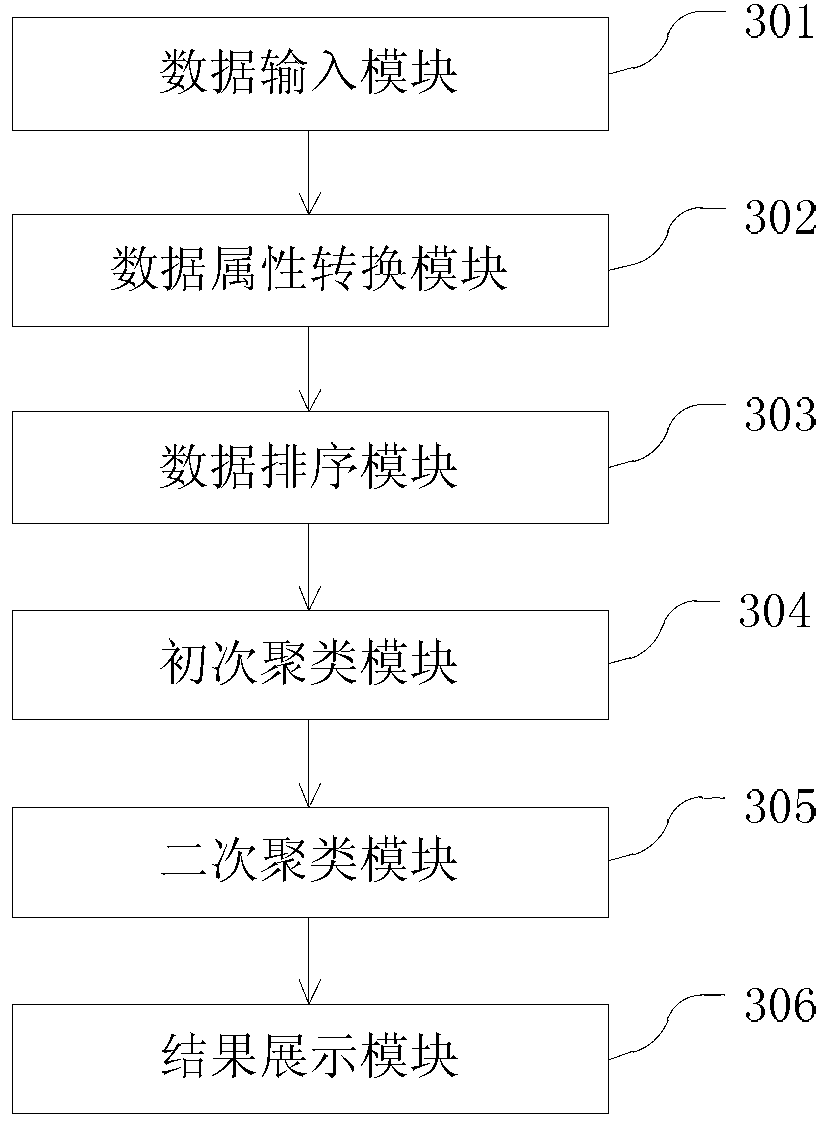
[0043] figure 1 A schematic flowchart of a fast clustering method based on set feature vectors according to an embodiment of the present invention is shown. figure 2 Then a detailed flowchart is shown. In general, the method includes a data attribute transformation step, a data sorting step, a primary clustering step and a secondary clustering step.
[0044] In step 101, the input mixed attribute data is converted into binary attribute data. For convenience of description, this step is referred to as a data attribute conversion step hereinafter.
[0045] In the data attribute conversion step, both the categorical attributes and the interval attributes in the data need to be converted into binary attributes. The metho...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More