

Text sentiment classification method facing Chinese Web comments
A technology for sentiment classification and text, applied in the field of data processing
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
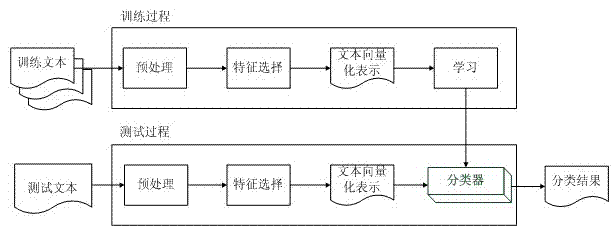
[0035] The overall process of text sentiment classification is as follows: figure 1 shown. The whole process can be divided into two parts: training process and classification process.
[0036] The basic flow of the training process is: training text preprocessing → feature selection → vectorized representation of text → training classifier. The specific processing is as follows:
[0037] 1. Given a manually classified training text set , to perform some preprocessing on it, such as Chinese word segmentation, stop word filtering, etc.
[0038] 2. Use statistics such as frequency to calculate the category of entries in the text The distribution in , after feature selection, get the local features of this category. Set the set of selected feature words ,in for category in the first feature words, Indicates the total number of feature words in this category. The union of the local feature word sets of all categories The set of global feature words that constitu...
Embodiment 2
[0052] Embodiment 2, vector space model
[0053] The Vector Space Model (Vector Space Model, VSM), proposed by Salton et al. of Harvard University in 1975, was first applied as an indexing method.
[0054] The basic idea of VSM is to use Bag of words (Bow) to represent text, and each entry is used as one dimension of the feature space coordinate system, and the text is regarded as a vector of feature space, and the angle between the two vectors is used to measure the similarity between two texts.
[0055] In VSM, each document is mapped to a point in a vector space spanned by a set of canonically orthogonalized feature vectors. Assuming that the set consisting of n feature items is F=(t1,t2,...,tn), the document is formalized as a vector di=(wi1,wi2,...,wik,...,win ), wik represents the weight of the kth feature item entry tk of di. The value of each dimension of the vector represents the weight of the feature item in the document, which is used to describe the importance...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More