

Method for realizing fast-speed short text bi-cluster
A short text, double clustering technology, applied in special data processing applications, instruments, electronic digital data processing, etc., can solve problems such as unreachable, poor results, and low clustering accuracy.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

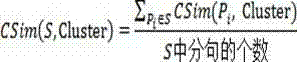
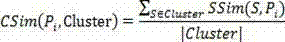
Examples
Embodiment Construction
[0036] The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
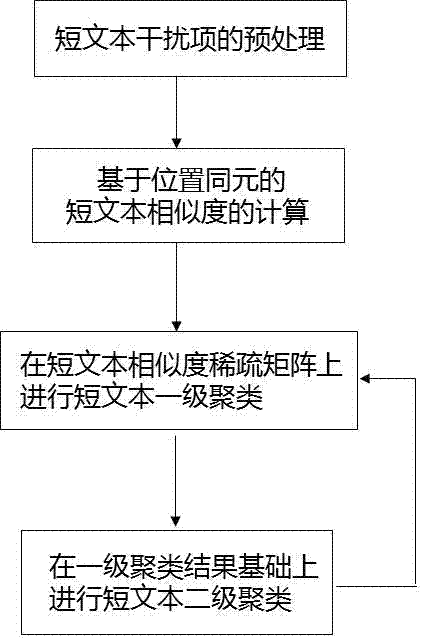
[0037] Such as figure 1 As shown, a fast short text biclustering method includes the following steps:
[0038] Step 1) Preprocessing of short text distractors, with the support of irrelevant word dictionary and part of speech dictionary, quickly identify and process irrelevant words and part of speech for short text.
[0039] Step 2) Based on the short text similarity calculation, the preprocessed two short text similarities are calculated to form a short text similarity sparse matrix.
[0040] Step 3) Perform first-level clustering of short texts on the short text similarity sparse matrix, and divide similar short texts into clusters one by one according to the settlement results of short text similarity.
[0041] Step 4) Perform secondary clustering of short texts on the basis of primary clustering results.
[0042] The above steps will b...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More