

Database query method based on body and restricted natural language processing
A technology of natural language processing and query method, which is applied in the field of database query based on ontology and limited natural language processing, which can solve the problems of large degree of limitation, limited vocabulary, and failure to meet practical requirements, so as to improve query efficiency , the effect of flexible structure
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
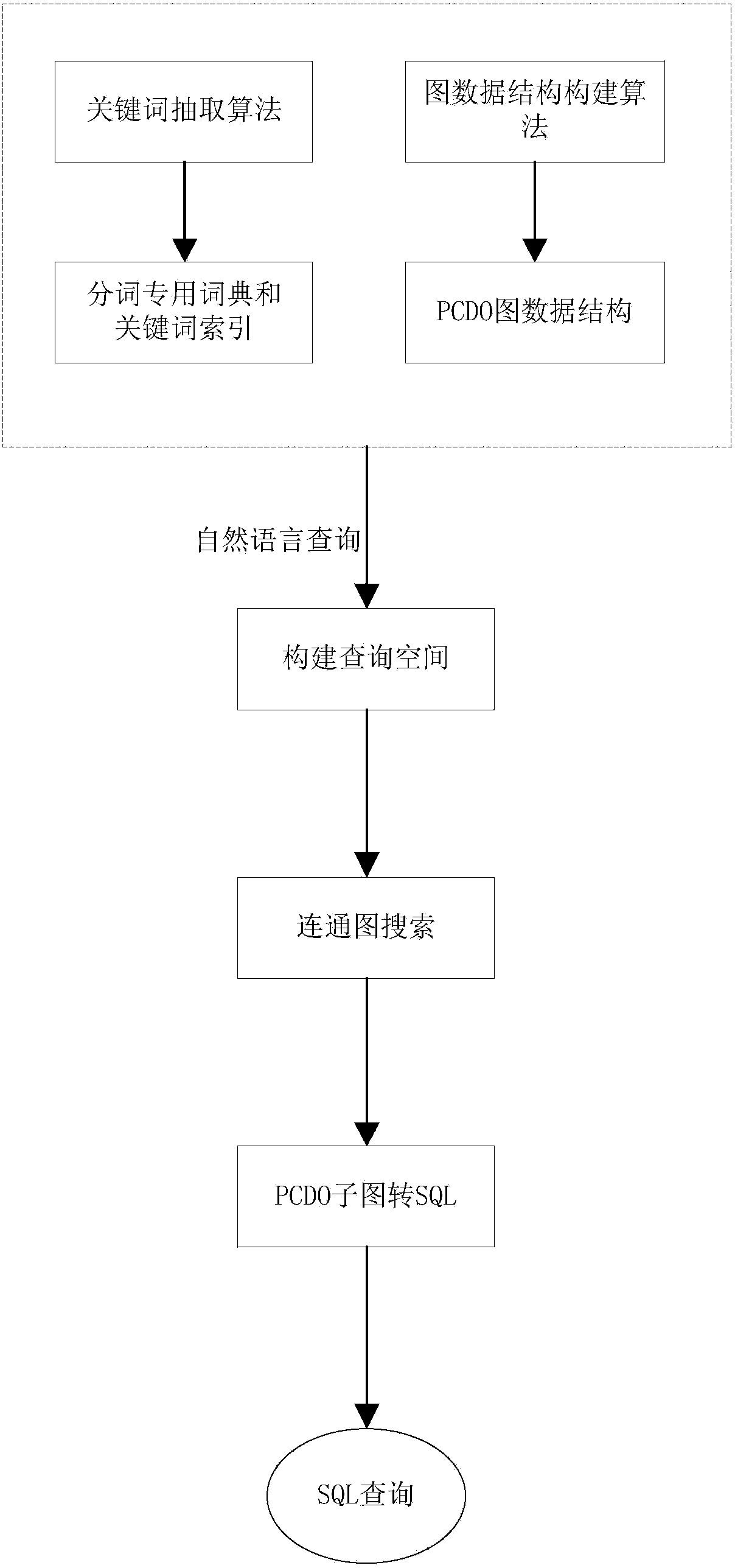
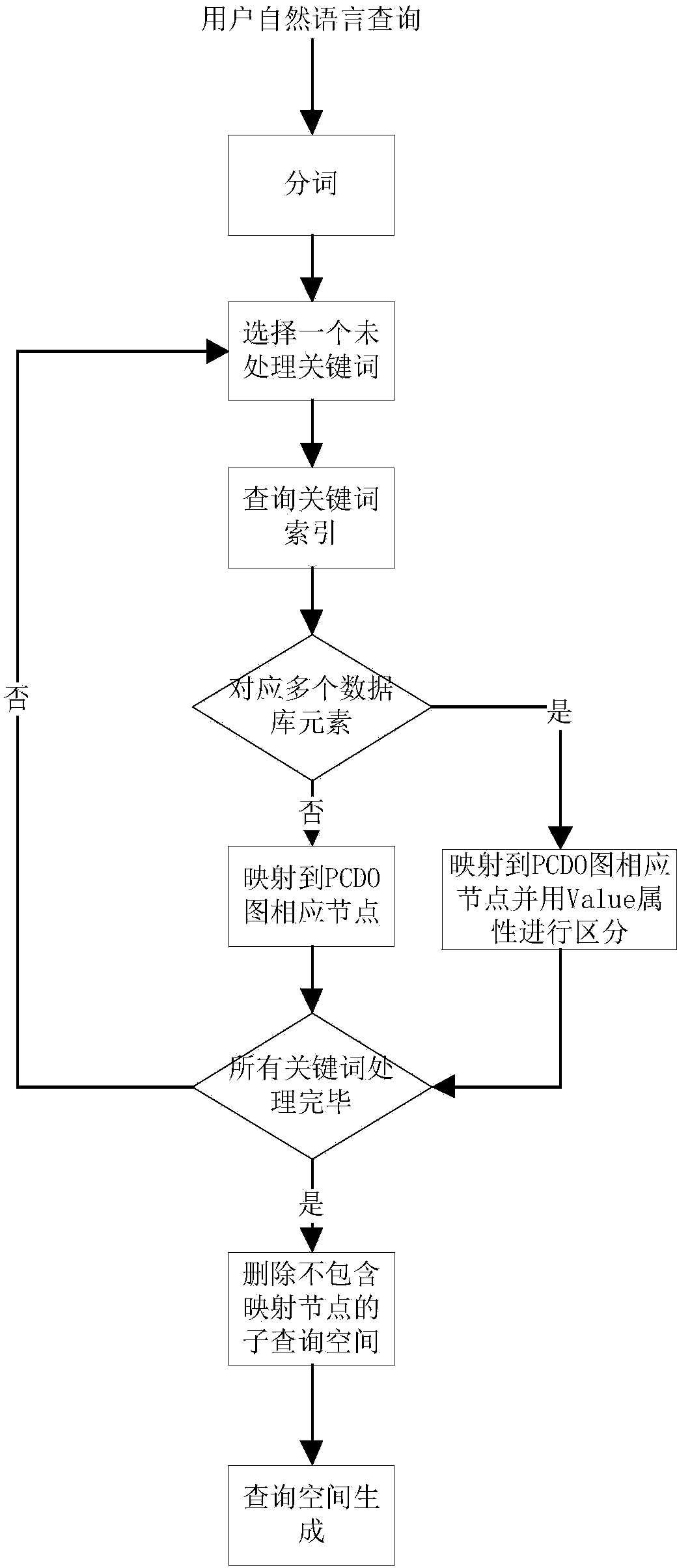
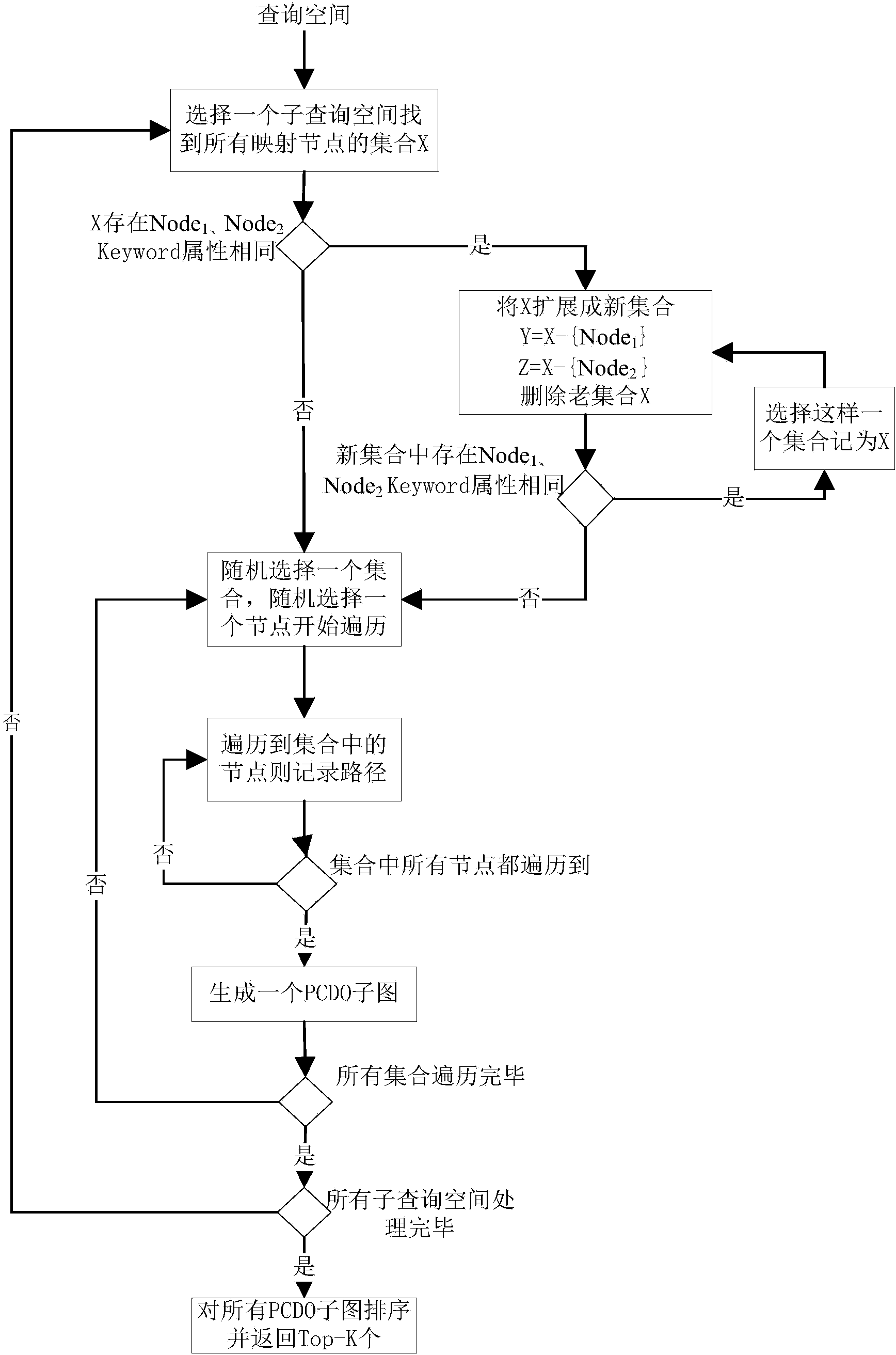
[0028] The implementation process of the present invention will be described in detail below in conjunction with the embodiments and the accompanying drawings.
[0029] The relational database query method based on ontology and limited natural language processing of the present invention comprises the following 6 steps:
[0030] 1) Ontology to PCDO graph data structure: Ontology is a specification proposed by the World Wide Web Consortium (W3C) for describing various resource information on the World Wide Web. The ontology in the present invention is based on the schema information of the relational database, according to It is constructed according to certain rules and is used to describe various resource information in the database. The ontology construction rules are as follows:
[0031] (a) Build a class in the ontology: For all the relational tables in the relational database, build a corresponding class in the ontology, and the class and the relational table correspond o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More