

A Semi-Supervised Method for Decomposing Variable Factors of Speech Features
A speech feature and semi-supervised technology, applied in the direction of instruments, character and pattern recognition, computer components, etc., can solve the problems of recognition rate impact, difficult to distinguish, poor recognition effect, etc., to avoid mutual interference and improve recognition accuracy Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
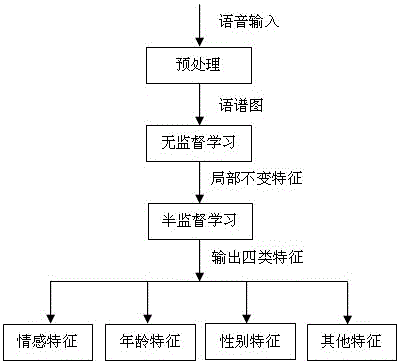
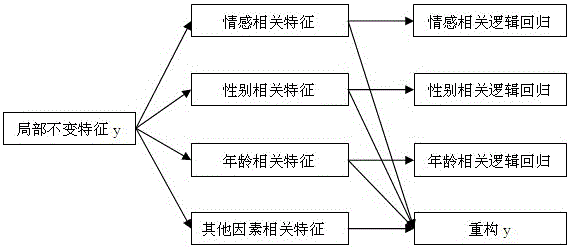
[0015] figure 1 The general idea of the method of the present invention is given. First, the speech is preprocessed to obtain the spectrogram, and the spectrogram blocks of different sizes are input into the unsupervised feature learning network SAE, and the convolution kernels of different sizes are obtained through pre-training, and then after convolution , pooling operation to form a local invariant feature y. y is used as the input of the semi-supervised convolutional neural network, and y is decomposed into four types of features by minimizing four different loss function terms.
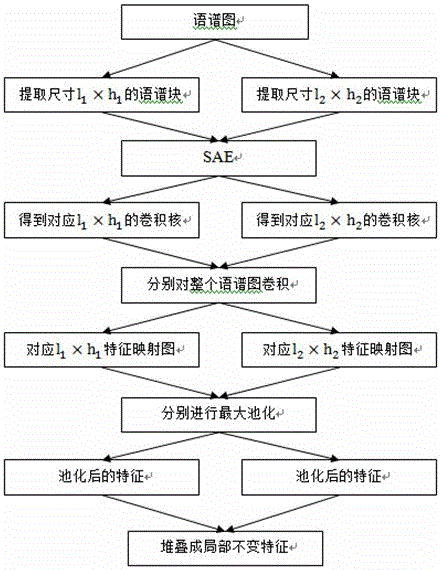
[0016] The preprocessed speech signal is divided into l i× h i Spectral blocks of different sizes, i represents the number of spectral blocks, different sizes of spectral blocks are input into the unsupervised feature learning network SAE, pre-trained to obtain convolution kernels of different sizes, and then use convolution kernels of different sizes to compare the entire language Convolve...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More