Associated data compressing method friendly to query
A technology of associated data and compression methods, applied in the field of big data, can solve problems such as aggravating performance problems and reducing query efficiency, and achieve the effect of improving the compression rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

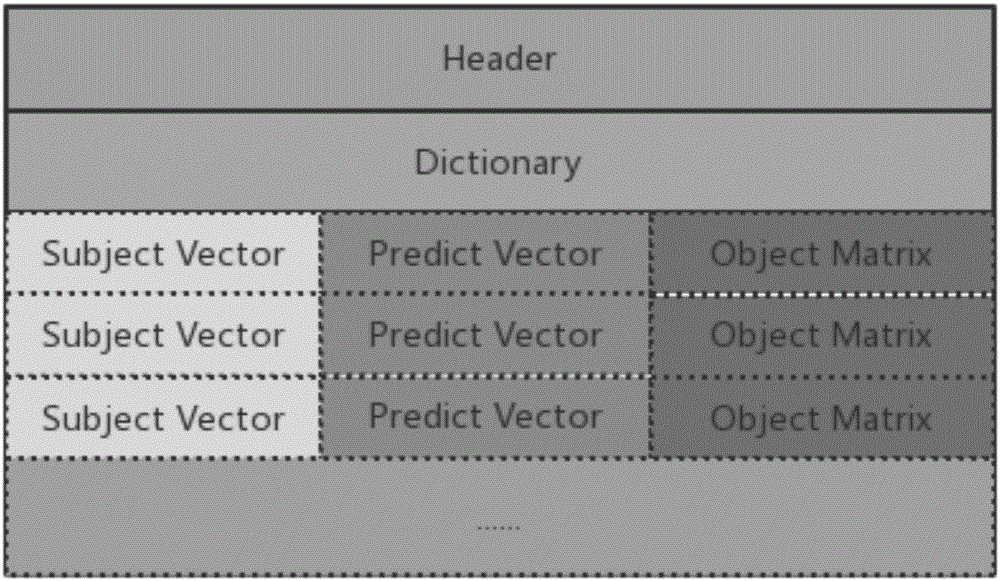

Examples
Embodiment Construction
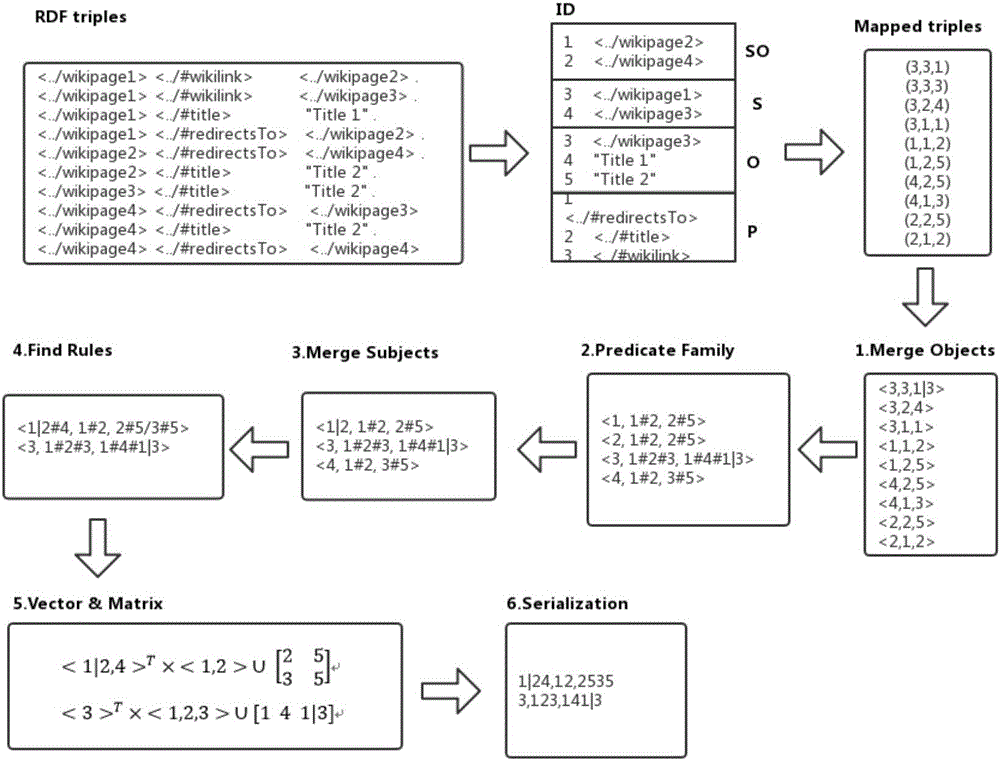
[0047] The technical solution of the present invention will be described in detail below in conjunction with the drawings and embodiments.
[0048] The technical solution provided by the present invention is an associated data set compression algorithm based on a relational matrix, specifically comprising the following steps:
[0049] 1. Define the memory model of triples, including three data segments of subject S, predicate P and object O;
[0050] 2. Input the associated data in N-Triple format and parse it to get a set of triples;
[0051] The detailed process is as follows:
[0052]2.1. Filter out lines starting with "#" or empty lines;
[0053] 2.2. Read each row of data and split the string by spaces;
[0054] 2.3. Map the segmented data to the subject, predicate and object of the triple to construct a triple;
[0055] 3. Build a dictionary and ID the triplet;
[0056] The detailed process is as follows:
[0057] 3.1. Flatten the triples obtained in the previous s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More