

Spark-based parallel association mining optimization method
An optimization method, k-1 technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve problems such as low efficiency, achieve high return on investment, reduce system I/O, and improve marketing decisions Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0016] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
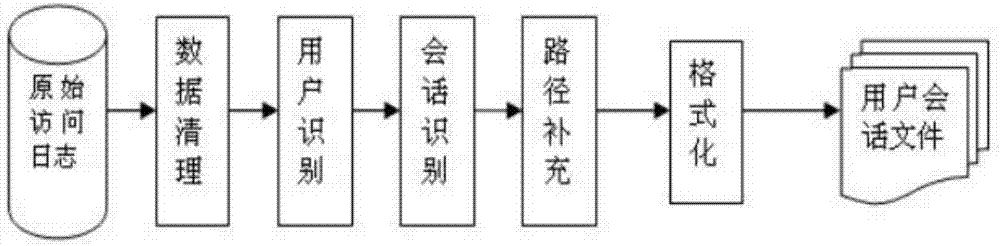
[0017] The steps of the Spark-based parallel association mining optimization method are as follows:
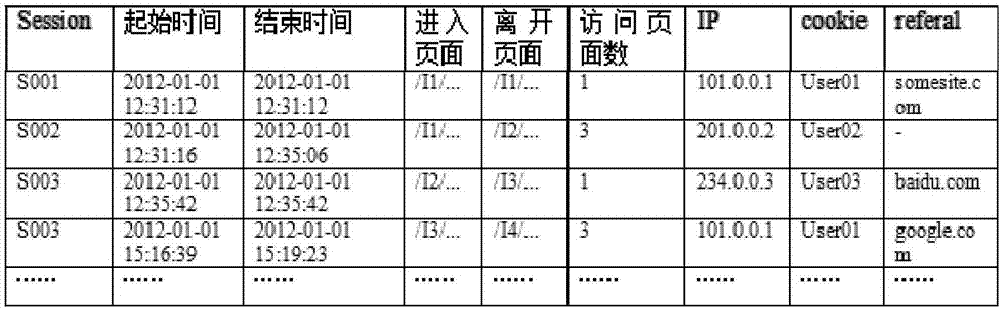
[0018] (1) Scan the transaction database D, clean the source data, simplify the data records, extract valid information, replace all data items with their corresponding numbers to generate a new transaction database D, and store it in HDFS. The new coded data are shown in Table 1.
[0019] Table 1
[0020]
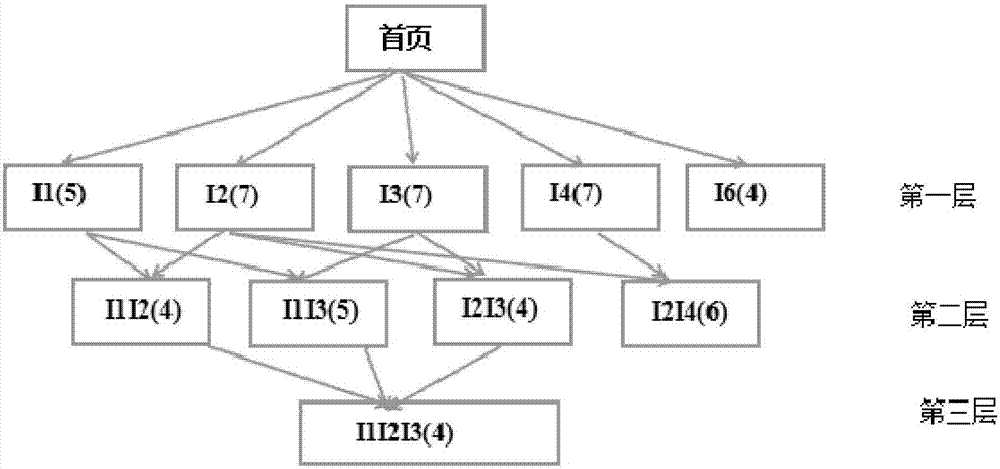
[0021] (2) Read the data set to be processed in HDFS and store it in the memory of each node of the cluster in the form of RDD, and realize the data structure conversion at the same time. ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More