

Multi-speaker-voice separation method based on deep learning
A separation method and multi-person voice technology, applied in speech analysis, instruments, etc., can solve problems such as instability, separation methods that cannot achieve separation effects, and voice signal complexity, and achieve excellent results
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0047] In order to make the purpose, technical solutions and advantages of the embodiments of the present invention clearer, the technical solutions in the embodiments of the present invention will be clearly and completely described below in conjunction with the drawings in the embodiments of the present invention. Obviously, the described embodiments It is a part of embodiments of the present invention, but not all embodiments. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
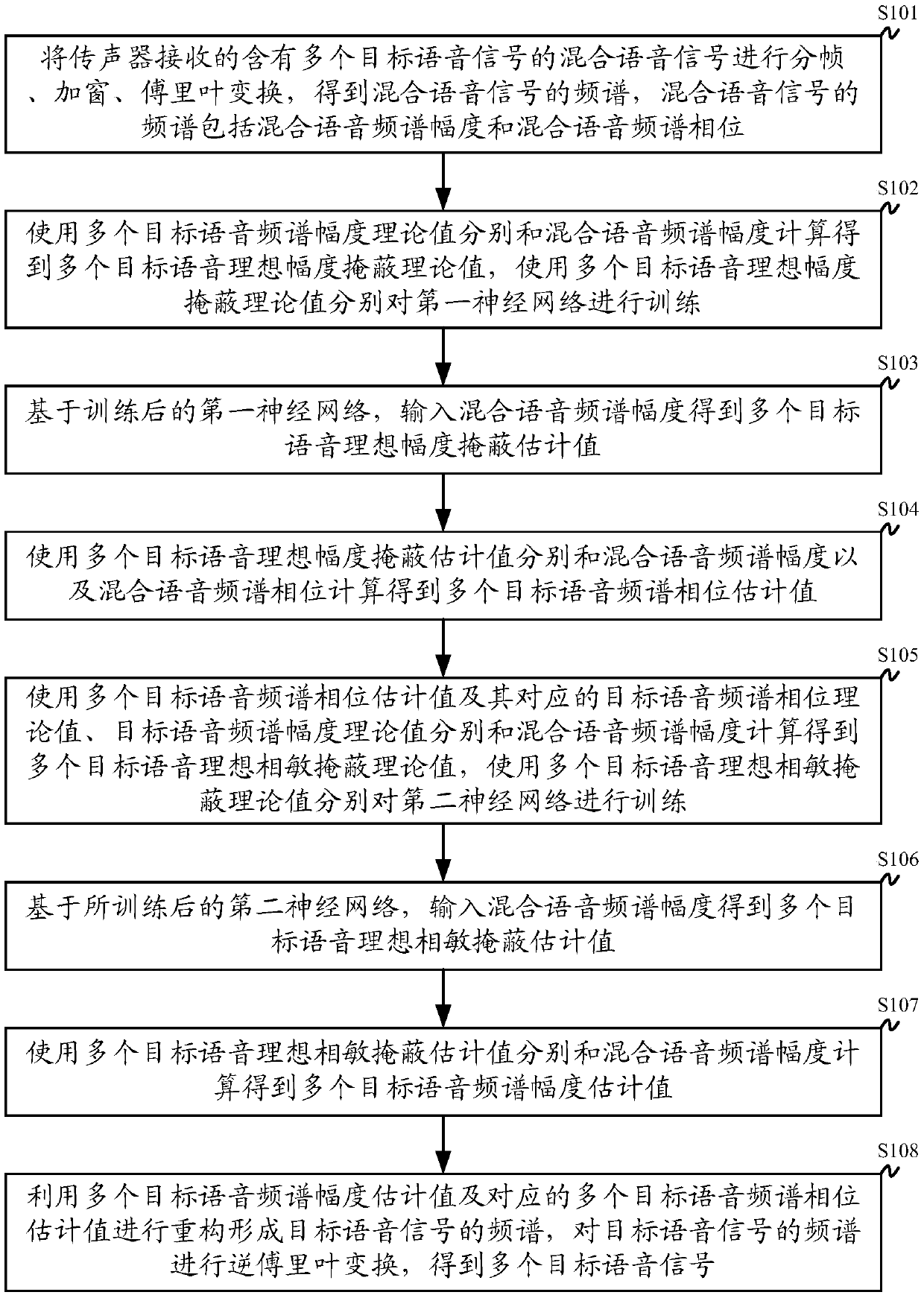
[0048] figure 1 It is a flow chart of a multi-person voice separation method based on deep learning. Such as figure 1 shown, including steps:
[0049] Step S101: Framing, windowing, and Fourier transforming the mixed voice signal containing multiple target voice signals received by the microphone to obtain the spectrum of the mixed voice s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More