Method and device for extracting entity related information, electronic device and storage medium
A technology related to information and entities, applied in the field of information processing, can solve problems such as the inability to meet the performance requirements of extracting entity-related information, poor user experience, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
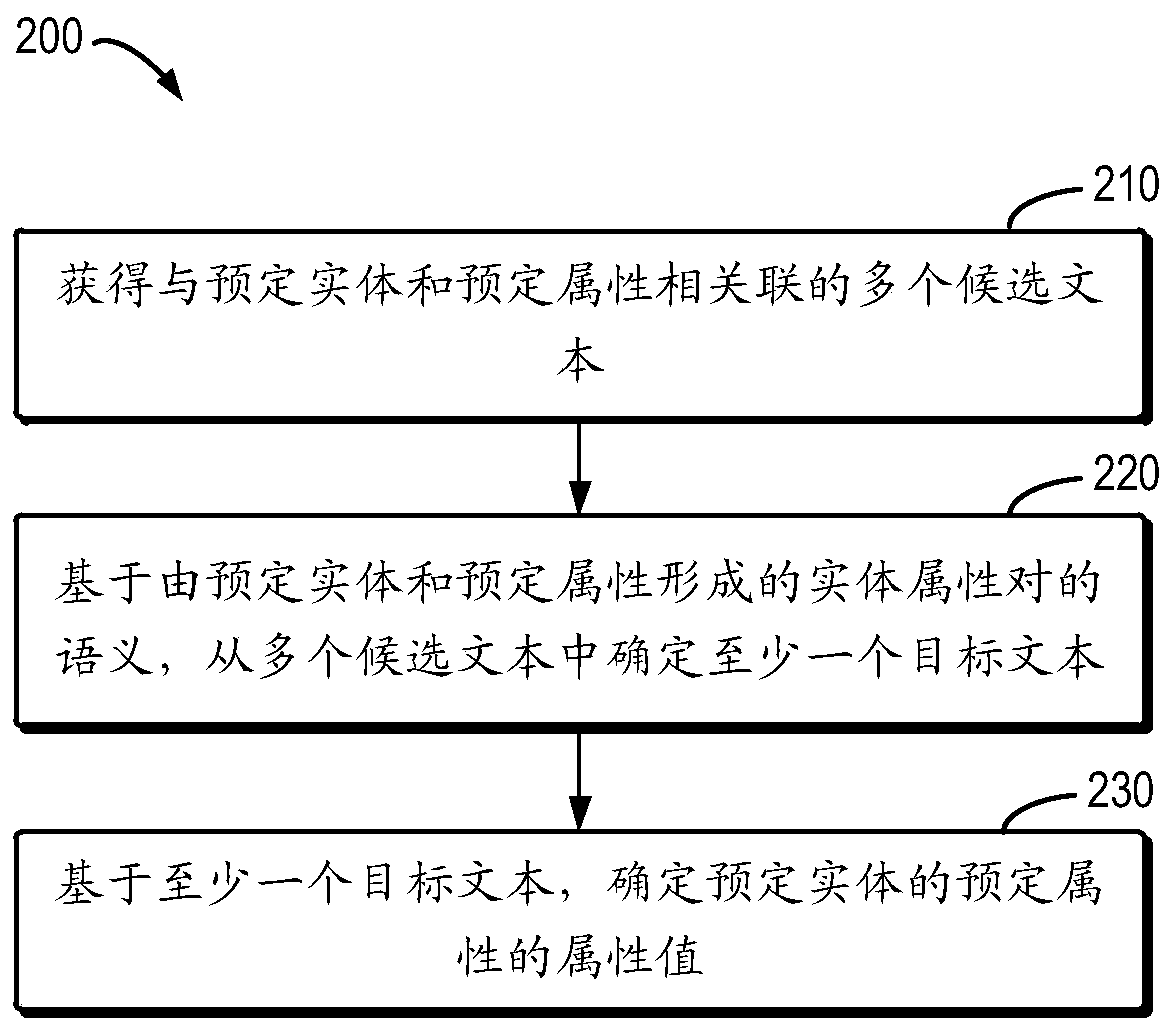
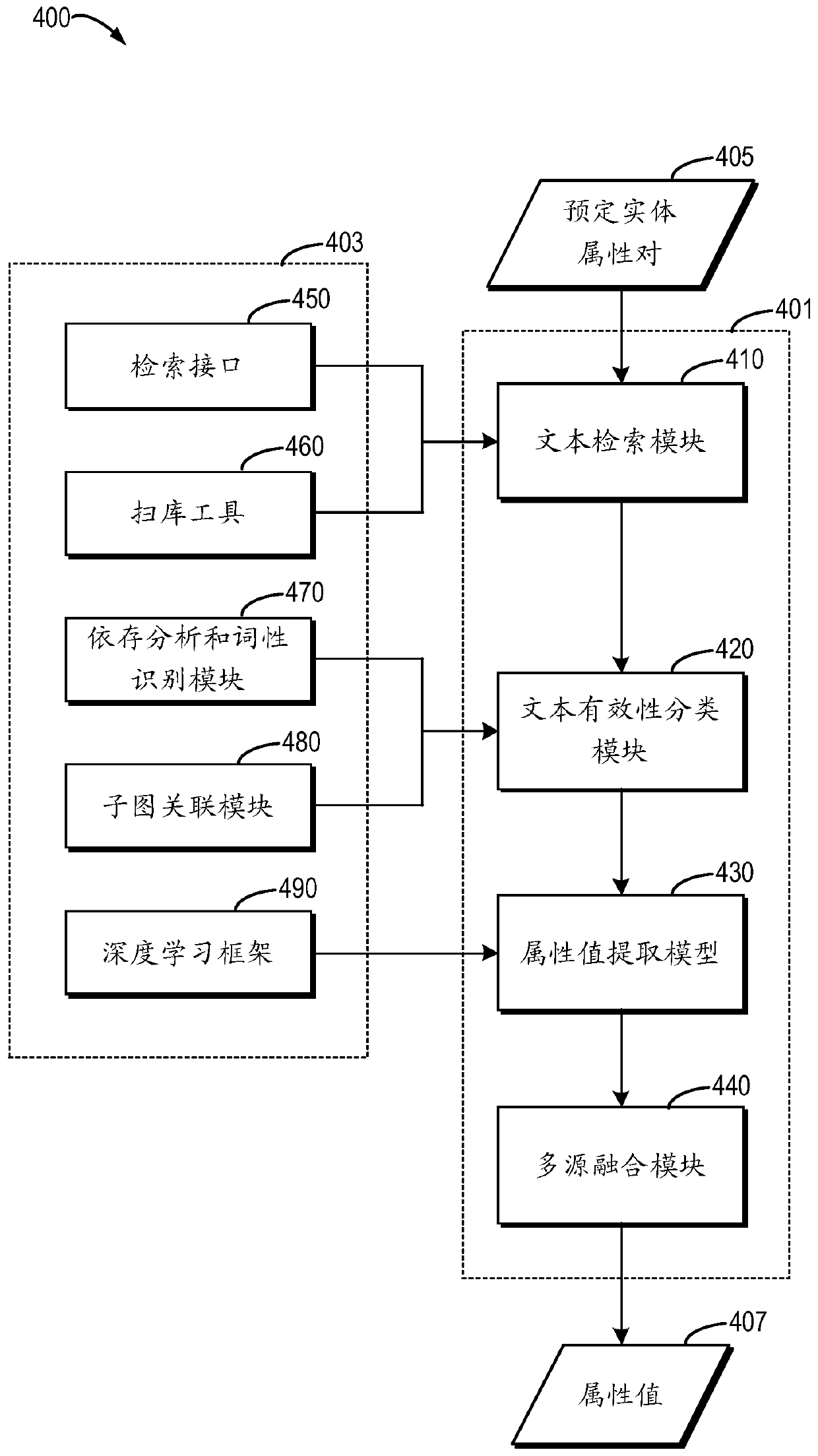
[0017] The principle and spirit of the present disclosure will be described below with reference to several exemplary embodiments shown in the accompanying drawings. It should be understood that these specific embodiments are described only to enable those skilled in the art to better understand and realize the present disclosure, rather than to limit the scope of the present disclosure in any way.
[0018] As mentioned above, traditional entity relationship extraction methods mainly include pure open extraction methods and structured extraction methods. However, there are some problems and deficiencies in these two traditional extraction methods. For example, the purely open extraction method is mainly used to process batch extraction of knowledge, but the extraction delay for new entities and new knowledge is relatively long, and the update time is long, so it cannot solve the problem of time-sensitive knowledge update. On the other hand, the main disadvantage of the struct...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More