

Method for solving video question and answer tasks needing common knowledge by using question-knowledge guided progressive space-time attention network
An attention and progressive technology, applied in video data retrieval, biological neural network model, metadata video data retrieval, etc., can solve problems such as insufficient answers and lack of information
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
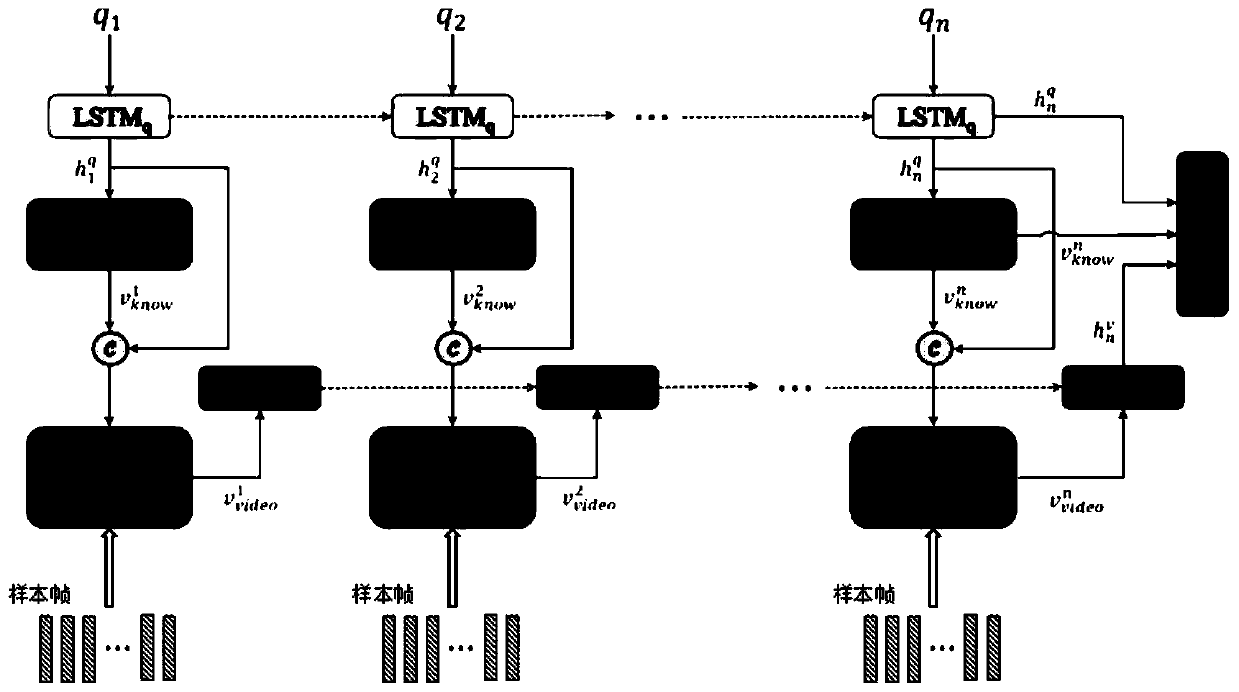
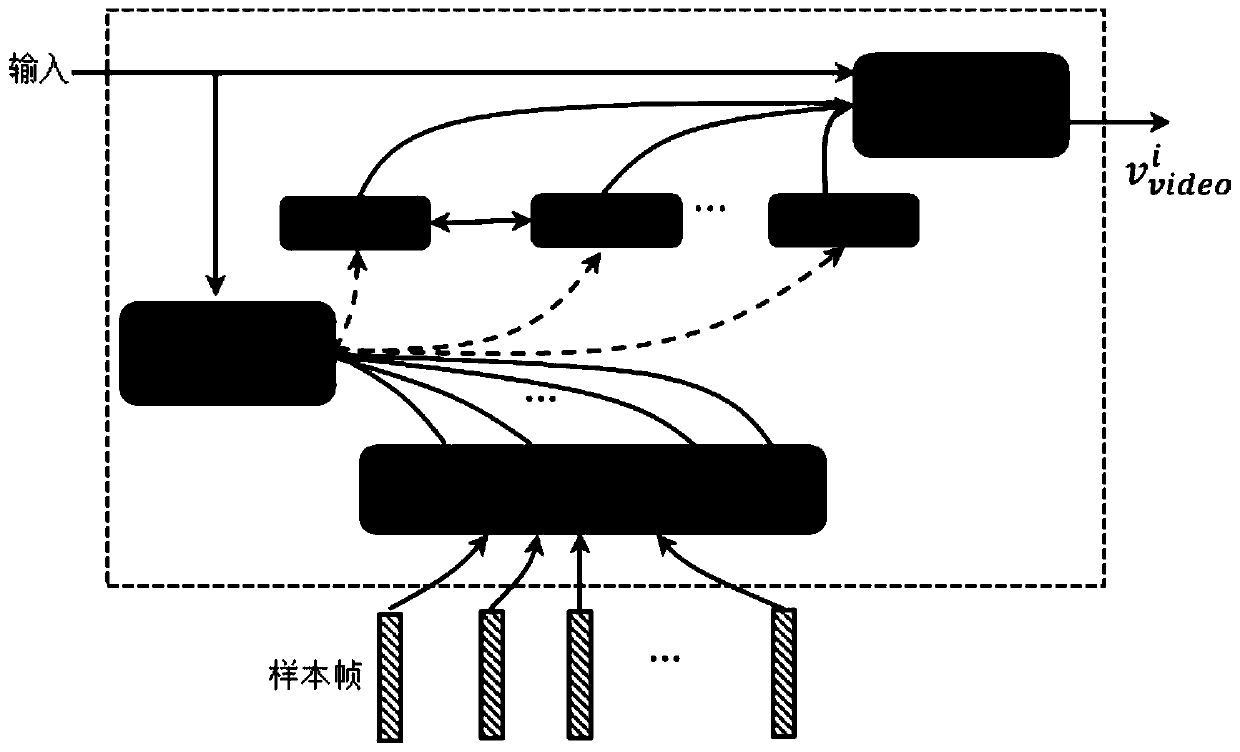
[0073] This embodiment constructs a video question answering dataset from the YouTubeClips video dataset, which contains 1,987 videos and 122,708 natural language descriptions collected from the YouTube website. Since the YouTubeClips video dataset contains rich natural language descriptions, the present invention generates questions and related answers according to an automatic question generation method. In this embodiment, the question-answer pairs generated in the YouTube-QA dataset are divided into five categories {"what", "who", "how", "where", "other"} according to the answer attributes. Details about the dataset are summarized below.
[0074] This example discards videos for which the question cannot be generated from the description. Therefore, the YouTube-QA dataset finally contains 1,970 videos, along with 122,708 natural language descriptions and 50,505 question-answer pairs. In this embodiment, the data set is divided into three parts: training set, verification...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More