

Speech recognition model word segmentation training method, system, mobile terminal and storage medium
A speech recognition model and training method technology, applied in speech recognition, speech analysis, instruments, etc., to achieve high recognition performance and reduce impact
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
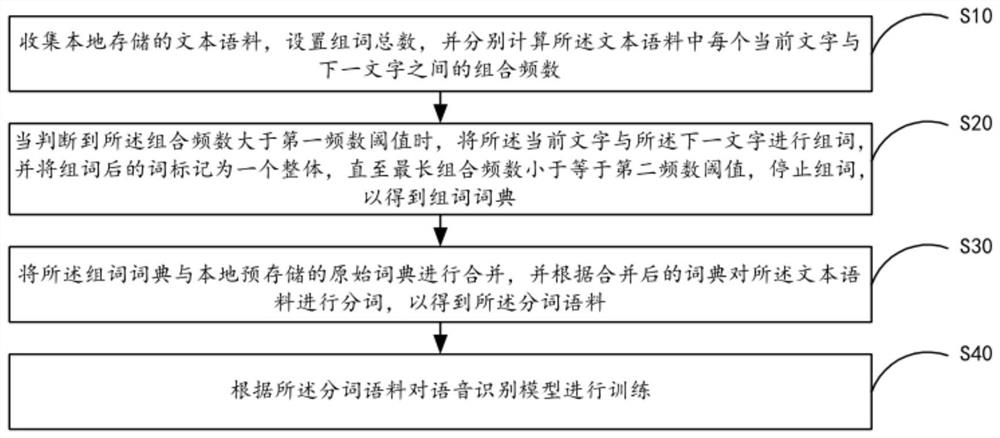
[0044] see figure 1 , is a flowchart of the speech recognition model word segmentation training method provided by the first embodiment of the present invention, including steps:
[0045] Step S10, collecting locally stored text corpus, setting the total number of word groups, and calculating the combination frequency between each current word and the next word in the text corpus;
[0046] Among them, preferably, due to the large number of words in the Chinese dictionary, even commonly used words also have more than 4000 words, and the number of words formed by these words increases exponentially. Therefore, it is necessary to collect a large amount of text corpus with a wide range of topics to The language model based on N-grams trained through the text corpus is credible, otherwise there will be great prejudice and poor generalization ability, resulting in the final speech recognition effect not meeting the requirements;
[0047] Specifically, in this step, the text corpus ...
Embodiment 2
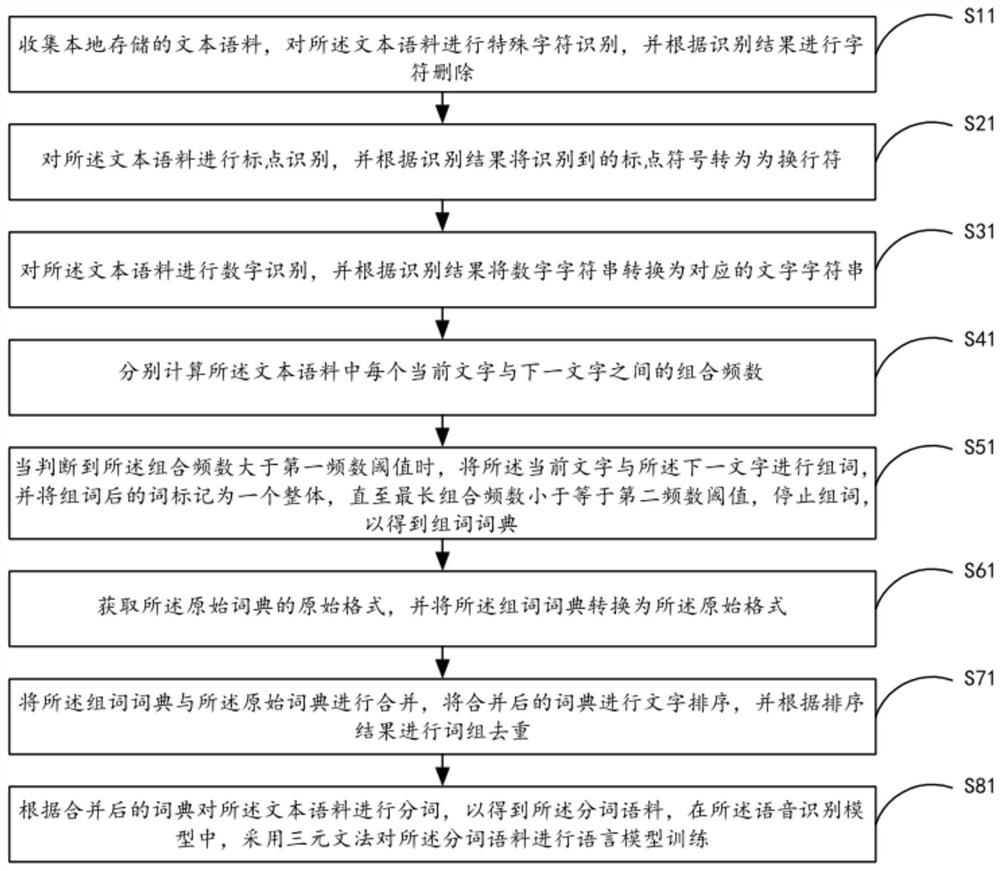
[0057] see figure 2 , is a flow chart of the speech recognition model word segmentation training method provided by the second embodiment of the present invention, including steps:
[0058] Step S11, collecting locally stored text corpus, performing special character recognition on the text corpus, and deleting characters according to the recognition result;
[0059] Among them, there may be characteristic characters stored in the collected text corpus, but because special characters generally do not exist in Chinese speech, in order to ensure the accuracy of subsequent word-to-word combination calculations, special characters need to be removed, so , before performing the subsequent word formation step, by performing special character recognition, so as to improve the accuracy of the speech recognition model word segmentation training method;
[0060] Step S21, performing punctuation recognition on the text corpus, and converting the recognized punctuation marks into line b...
Embodiment 3
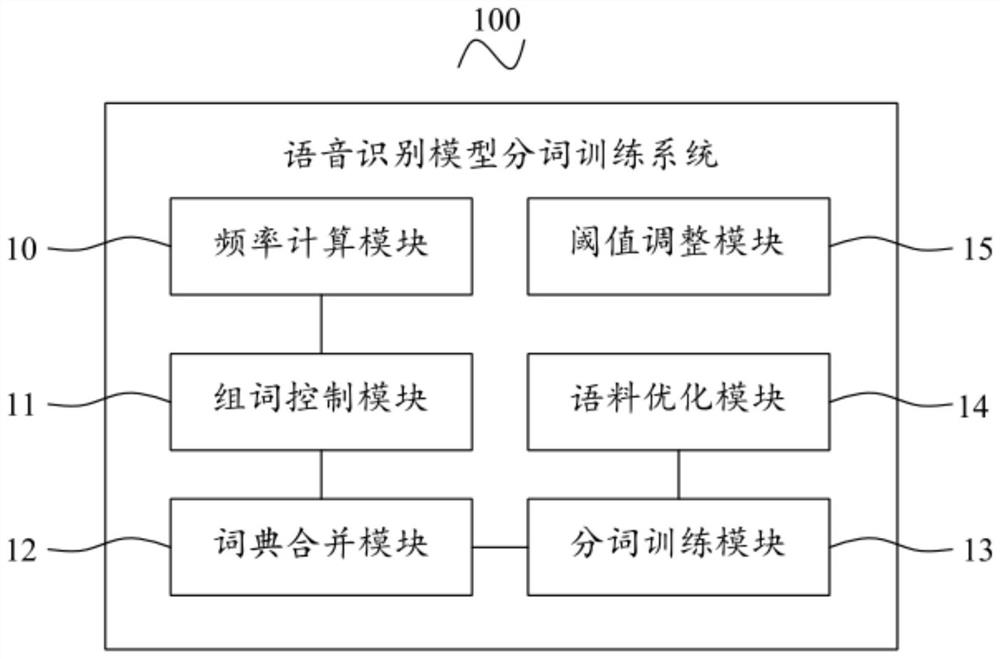
[0079] see image 3 , is a schematic structural diagram of the speech recognition model word segmentation training system 100 provided by the third embodiment of the present invention, including: a frequency calculation module 10, a word group control module 11, a dictionary merging module 12 and a word segmentation training module 13, wherein:
[0080] Frequency calculation module 10 is used to collect the text corpus of local storage, set the total number of group words, and calculate the combination frequency between each current word and the next word in the text corpus respectively;
[0081] Word grouping control module 11, for when judging that described combination frequency is greater than the first frequency threshold value, carry out word grouping with described current character and described next character, and the word mark after grouping word as a whole, until final If the long combination frequency is less than or equal to the second frequency threshold, word fo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More