

Webpage data crawling method and device and webpage login method and device
A technology of web page data and login method, applied in the network field, can solve the problem of easy failure of web page data, and achieve the effect of avoiding multiple repeated logins
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0077] Exemplary embodiments of the present invention will be described in more detail below with reference to the accompanying drawings. While exemplary embodiments of the present invention are shown in the drawings, it should be understood that the present invention may be embodied in various forms and should not be limited by the embodiments set forth herein. Rather, these embodiments are provided so that the present invention will be more thoroughly understood, and will fully convey the scope of the present invention to those skilled in the art.
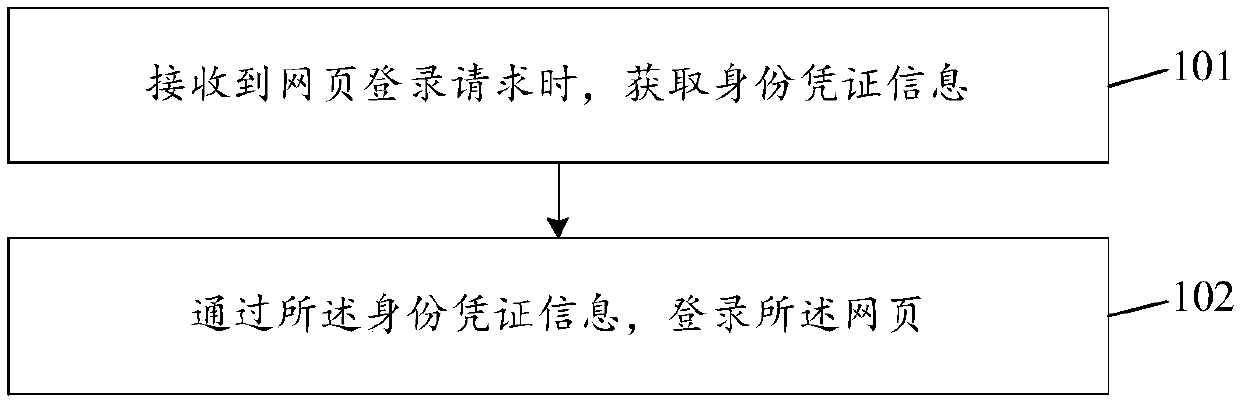
[0078] In order to solve the problem that access requests are restricted or prohibited due to multiple logins in the process of logging in to a website that is set with account name and password verification, the embodiment of the present invention provides a web page login method, such as figure 1 As shown, the method includes:
[0079] 101. When a webpage login request is received, obtain identity credential information.
[0...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More