Environment aware voice-assistant devices, and related systems and methods
A technology of speech and speech output, applied in the system field of intelligibility and user experience, which can solve problems affecting the perceived quality or intelligibility of synthesized speech
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
[0055] figure 1 An example of a first system 10 is shown for adapting playback by a voice assistant device to the environment to preserve or improve the intelligibility of synthesized speech or other playback speech. System 10 may include audio appliance 100 . Audio appliance 100 may embody, for example, a computing device. In some aspects, an audio appliance is embodied as a mobile communication device, such as a smartphone or tablet, or a personal or home assistant device, such as a smart speaker. Audio appliance 100 may include a voice assistant application (not shown) configured to listen for, understand, and respond to a user's spoken requests or commands. Alternatively, the voice assistant application may reside on a different device, such as a network-connected device, or the voice assistant application may be distributed among multiple network-connected devices.
[0056] The appliance 100 may be configured to listen for and respond to speech activation commands, eg,...
Embodiment 2
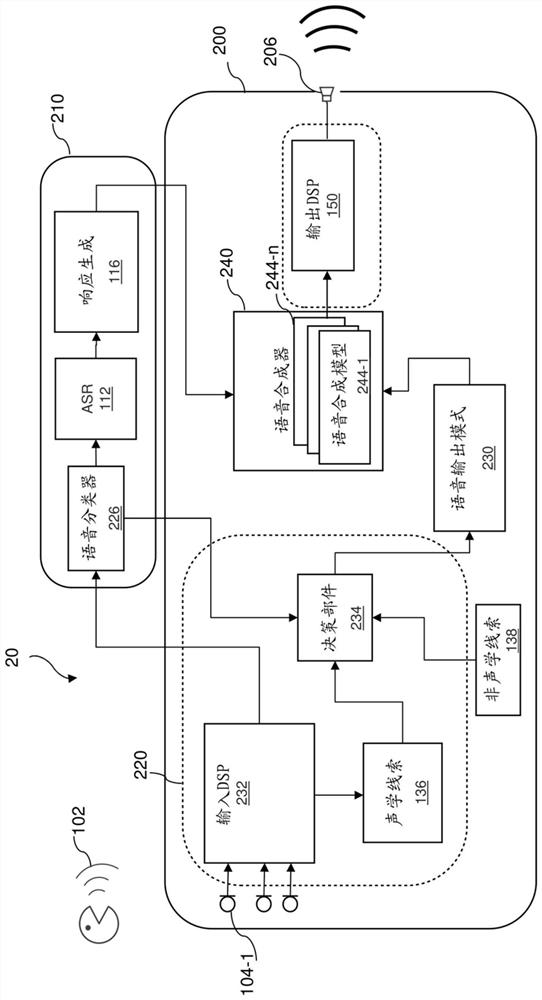
[0078] figure 2 An example of a second system 20 for adapting playback by a voice assistant device to the environment to preserve or improve the intelligibility of synthesized speech or other playback speech is shown. System 20 may include audio appliance 200, and may be similar in some respects to figure 1 System 10. For example, system 20 may also use output DSP 150 . However, Embodiment 1 selects from different speech synthesis parameters, and Embodiment 2 selects from different speech synthesis models. In system 20, speech synthesizer 240 may include a plurality of speech synthesis models, such as models 244-1, . . . 244-n. The plurality of speech synthesis models may include a speech synthesis model specific to low voice speech, a second speech synthesis model specific to Lombard effect speech, and a third speech synthesis model specific to normal speech. More, fewer or different speech synthesis models may be included. For example, there may be a single speech synt...
Embodiment 3
[0084] image 3 An example of a third system 30 for adapting playback by a voice assistant device to the environment to preserve or improve the intelligibility of synthesized speech or other playback speech is shown. System 30 may include audio appliance 300, and may be similar to figure 1 and figure 2 Systems 10 and 20 are shown in respectively. Embodiments 1 and 2 affect how the speech is synthesized relative to the selected speech output mode, while in embodiment 3 the synthesized speech is modified according to the speech output mode after synthesis. For example, system 30 may also use input DSP 132, speech classifier 126, ASR system 110, and output DSP 150 as in system 10, or may use input DSP 232, speech classifier 226, ASR system as in system 20 210 and output DSP 150.
[0085] Speech synthesizer 340 may synthesize speech without input from decision component 334 . In some cases, speech synthesizer 340 may operate remotely from audio appliance 300 .
[0086] Inst...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com