

Webpage Text Extraction Method Based on Deep Learning
A deep learning and text technology, applied in the Internet field, can solve problems such as inappropriate web page design, complex implementation and maintenance, and cumbersome rule definition, improve model generalization ability, and solve problems of robustness and generalization. , the effect of improving cost
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
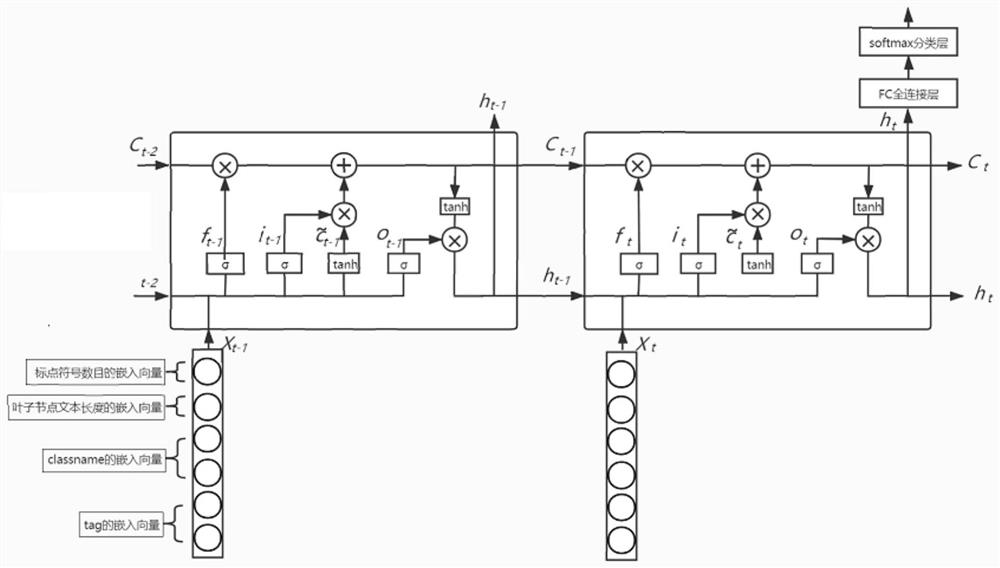
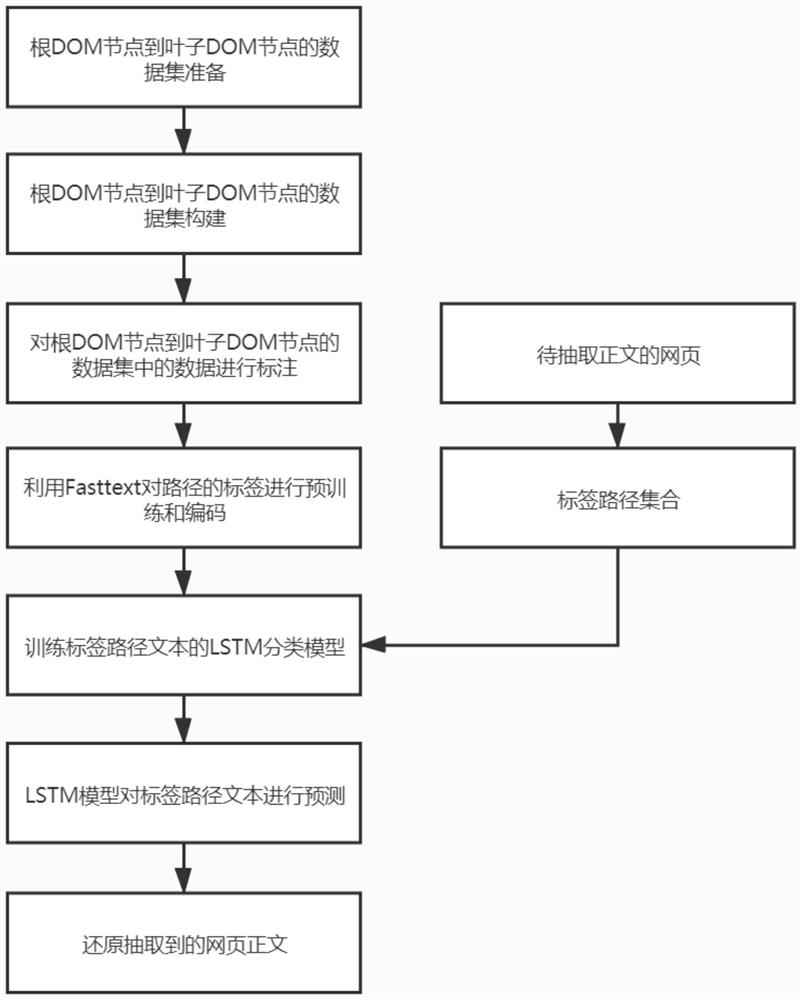
[0052]通过预训练的fasttext模型对输入的标签路径进行编码表示,得到了LSTM 模型的输入,结合标签路径的分类进行训练LSTM,本发明中的LSTM模型直接使用PyTorch框架进行实现。参数设置如下:最大标签路径的序列长度设为 15(长于15个的标签路径只输入前15个标签)、dropout为0.3,、隐藏层单元数为128,LSTM层数为2,输出为2个类(是正文或不是正文),优化器为 Adam,学习率为0.001,损失函数为交叉熵函数,batch size是32,至少经过 100个epochs,之后只要连续20个epochs都没有产生更优的loss和f1score,则停止训练。通过这样的方式得到了正文抽取模型。对测试集中的304篇网页进行抽取正文测试,实验结果如图4实线。
[0053]以上对比例1,对比例2,以及实施例1中,采用的模糊字符串匹配的方式进行效果评估,先用这三个工具对验证集的300余个网站进行正文提取,另外根据标注提取一份正文作为标准答案。为了消除分割方式造成的误差,统一将结果的空格和换行符全部取出,用FuzzyWuzzy实现模糊字符串匹配, FuzzyWuzzy是一个基于Levenshtein距离的一个字符串相似度衡量工具,而 Levenshtein距离表现的是一个字符串至少需要变换几个字符才能变成另外一个字符和标准长度。FuzzyWuzzy衡量字符串相似度的度量是Levenshtein距离和两个字符串平均长度的比率,这个得分越高,说明两个字符串越相似。
[0054]图4的横坐标是网页序号,纵坐标是某个工具在这个网页提取的正文和标准答案的相似度,相似度越高,则说明工具的性能越好,虚线是Readability,点线是Newspaper3k,实线是基于本发明LSTM模型的正文提取结果。从图中明显看出,本发明的提取正文效果要好。
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More