

Multi-speaker speech synthesis method based on probability generation and non-autoregression model
An autoregressive model and speech synthesis technology, applied in speech synthesis, speech analysis, instruments, etc., can solve problems such as low similarity and insufficient generalization
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
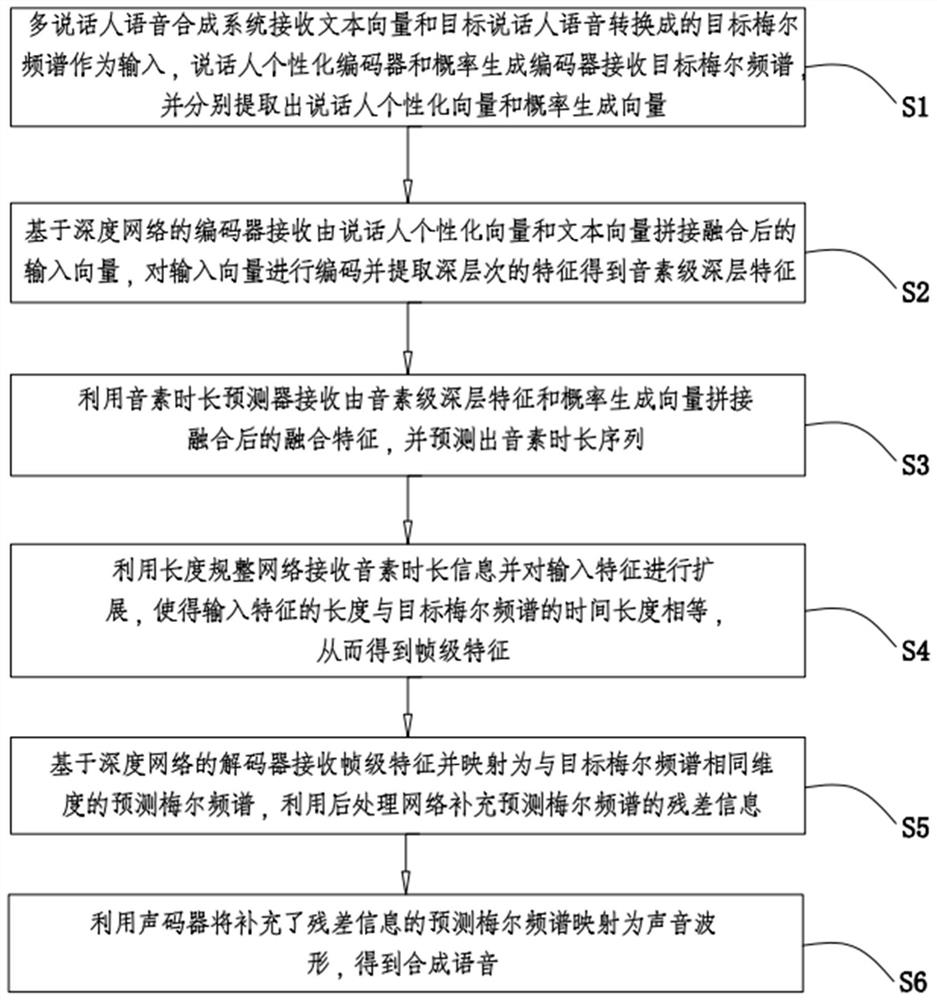
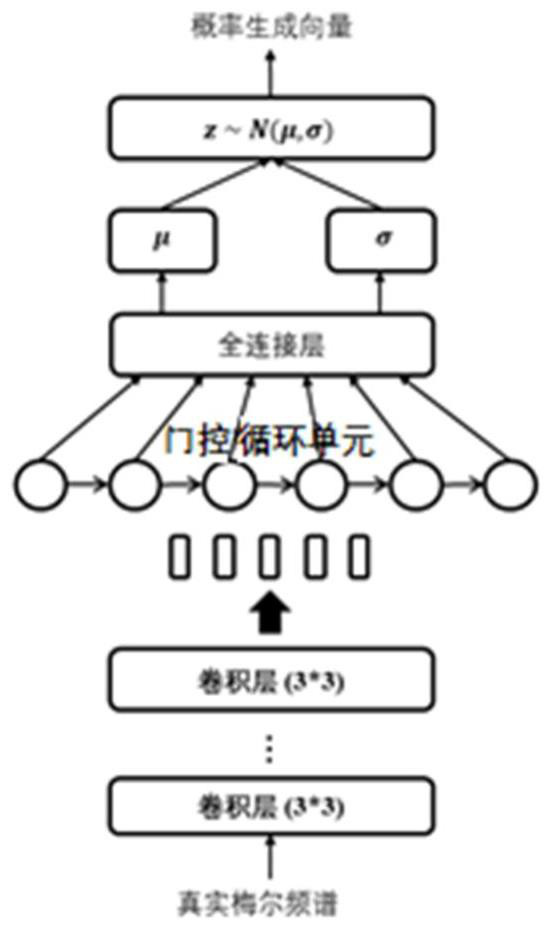
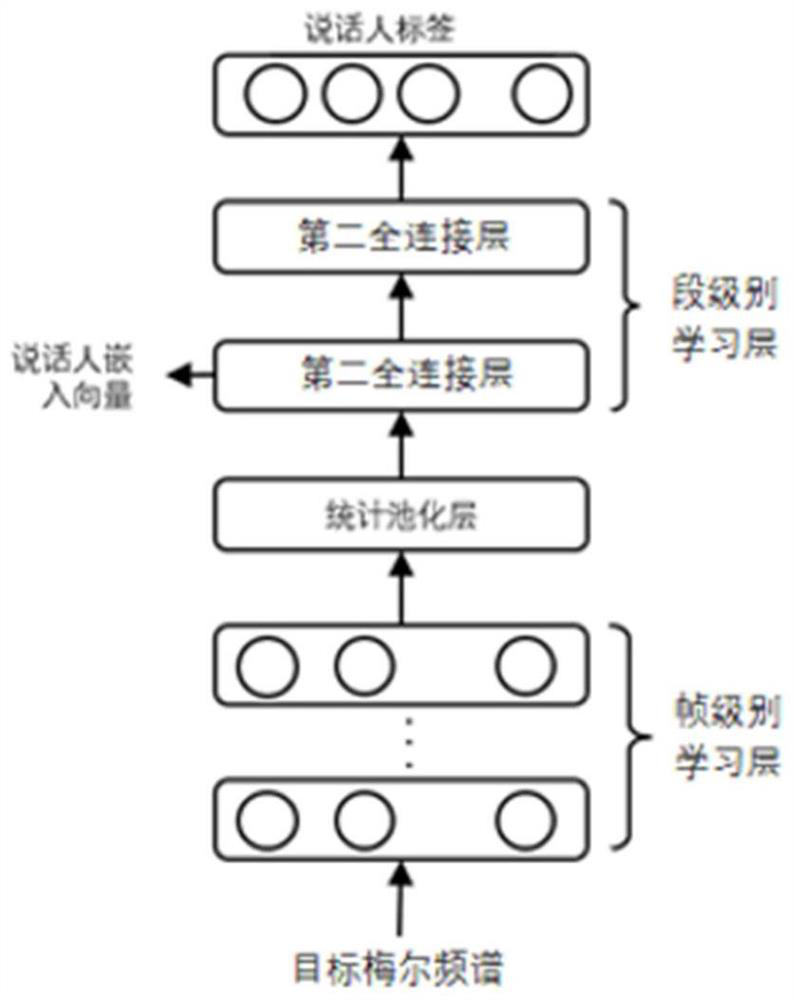
[0046] The characteristics and exemplary embodiments of various aspects of the present invention will be described in detail below. In order to make the purpose, technical solutions and advantages of the present invention more clear, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only configured to explain the present invention, not to limit the present invention. It will be apparent to one skilled in the art that the present invention may be practiced without some of these specific details. The following description of the embodiments is only to provide a better understanding of the present invention by showing examples of the present invention.
[0047] It should be noted that in this article, relational terms such as first and second are only used to distinguish one entity or operation from another entity or operation, and ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More