

Figure information disambiguation treatment method based on social network and name context
A social network and character information technology, applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., to achieve the effect of disambiguation processing
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach 1
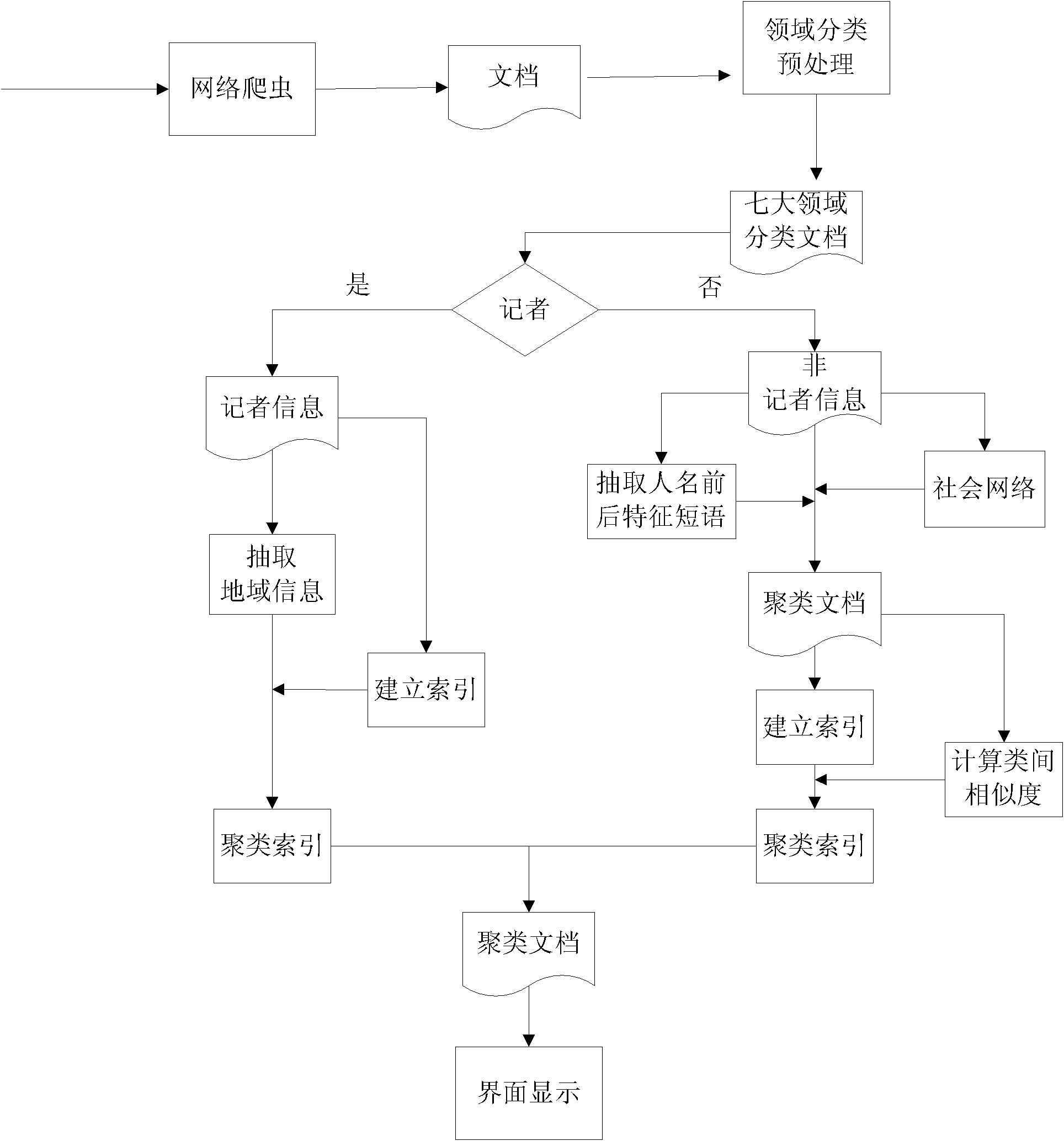
[0007] Specific embodiment one: this embodiment comprises the following steps: one, the user inputs a name to be retrieved, utilizes a search engine, such as Google API, (that is, the application programming interface provided by Google Inc.) to complete the retrieval, and the retrieved webpage is downloaded to the local computer; 2. The above-mentioned web pages are respectively extracted from the text, word segmentation and part-of-speech tagging to form a document; the word segmentation is about to divide each sentence into entries with independent meanings, and the part-of-speech tagging refers to marking each word at the same time Such as parts of speech such as nouns and verbs, word segmentation and part-of-speech tagging can respectively adopt the widely used forward maximum matching method and N-grams. 3. Classify the documents first by using the person domain information, and then use the social network and context information to cluster the person domain information, ...
specific Embodiment approach 2
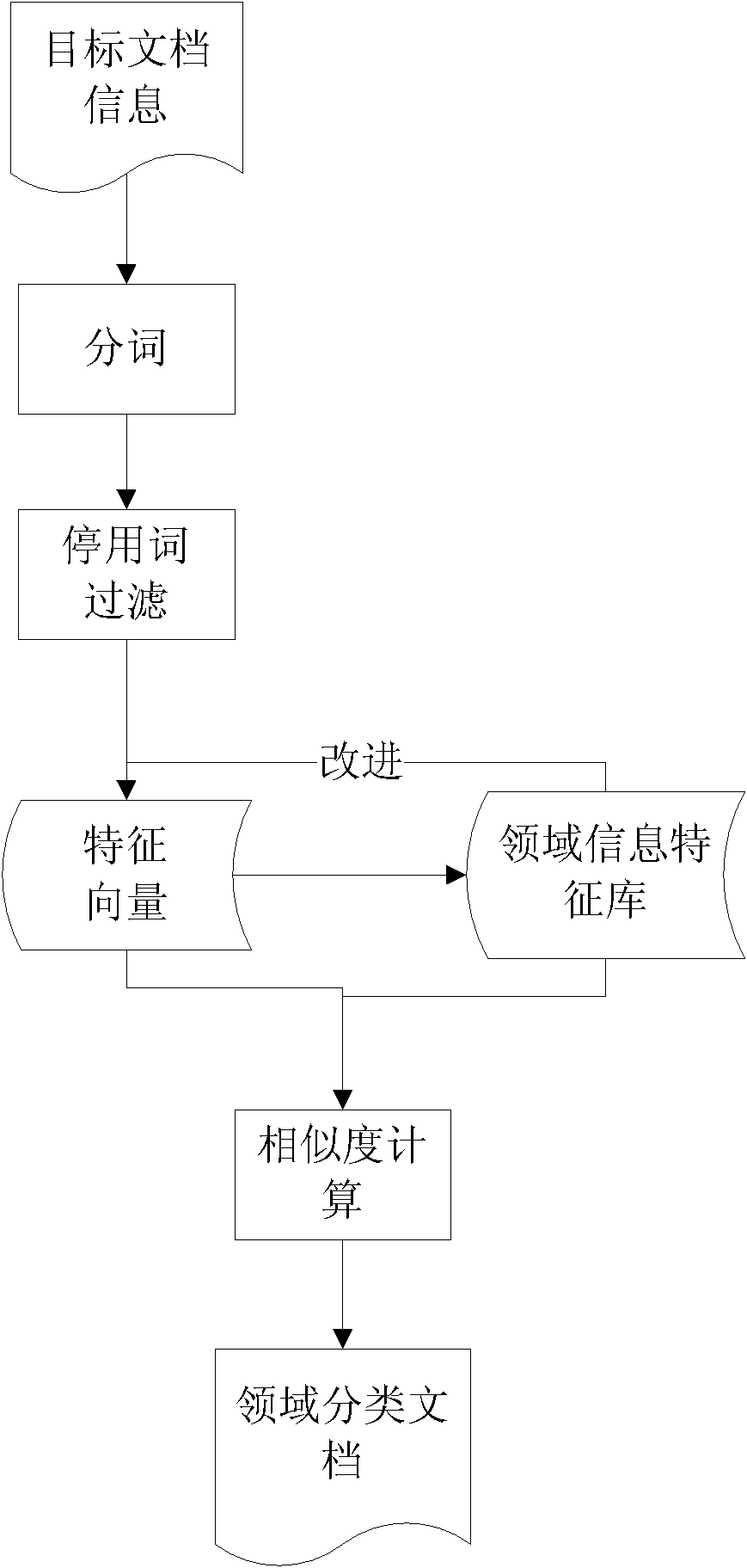
[0008] Specific Embodiment 2: The difference between this embodiment and Embodiment 1 is that in the third step, the classification is carried out by using the person field information in this way: pre-classify based on the person field information, and divide the person information into entertainment, administration, and military , science and education, sports, medical care, economy and other seven categories, for each category, manually mark several representative documents, and then extract the feature information of each field category to form a field feature library, then use SVM for document classification processing, Simply classify people in reality. In this way, the characters in one type are separated from the characters in other types, and there is no comparability between them. You only need to process the information of the characters in the same field category, and aggregate the characters in the same category. Class processing, so as to finally realize the disa...
specific Embodiment approach 3
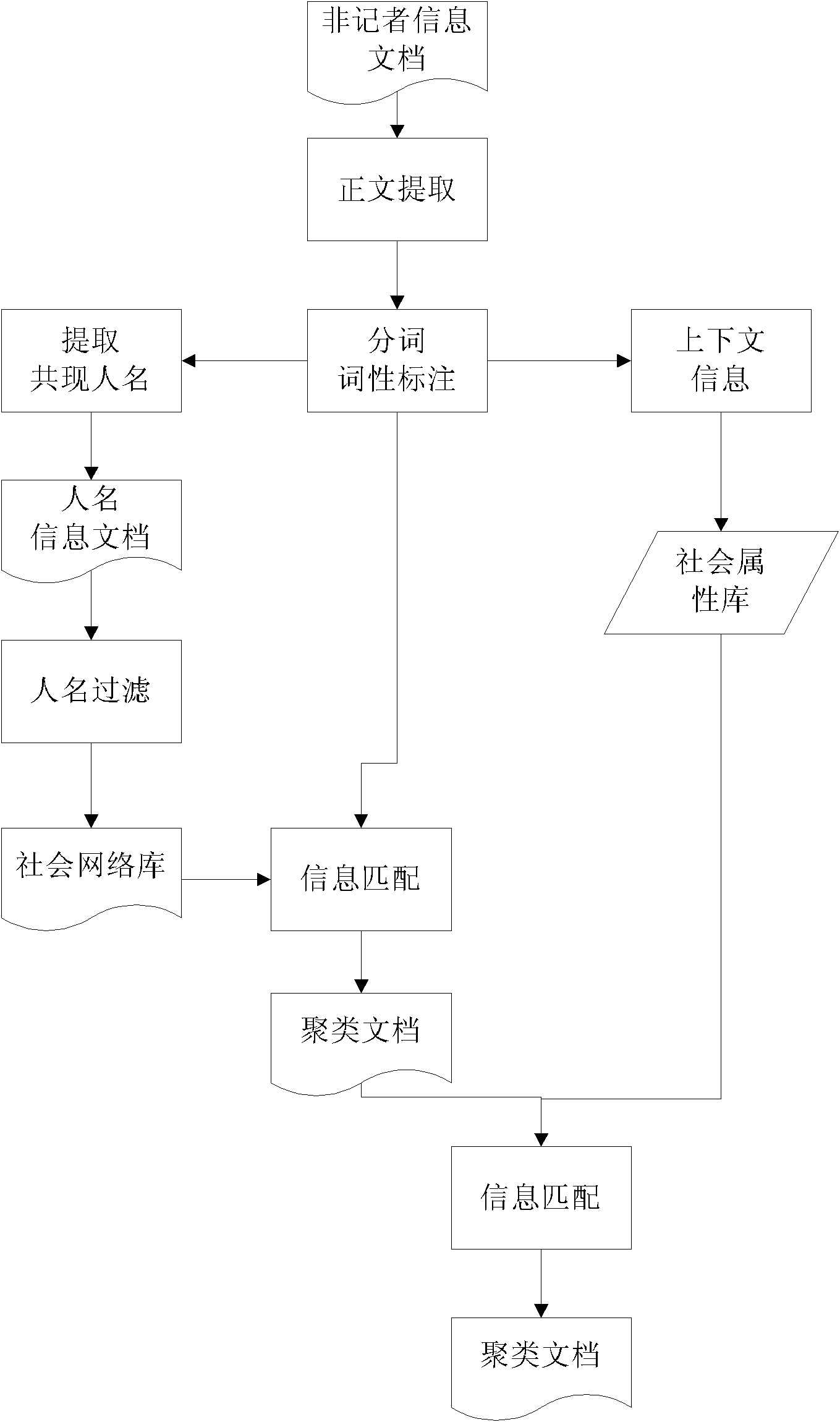
[0009] Embodiment 3: The difference between this embodiment and Embodiment 1 is that in the third step, the social network and context information are used to cluster the person domain information in this way: the context information of other person information appearing in the document It can well show some unique attributes of characters that are used to distinguish others. The co-occurring names in documents constitute their social network, and the contextual information constitutes their social attributes. Retrieve person name A, if person names A and B appear in document D1, and person names A and B also appear in document D2, then documents D1 and D2 refer to the same real person entity, then they correspond to the same category, otherwise D2 If the names A and C appear in , they are considered to be different categories of characters. And in the process of processing, its social network is constantly expanding, that is, if the names A, B, and C appear in document D1, a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More