

Method for updating voiceprint feature model and terminal
A voiceprint feature and model update technology, applied in speech analysis, speech recognition, instruments, etc., can solve the problem of inability to guarantee, the voiceprint feature model cannot improve the recognition accuracy, etc., to improve accuracy, improve accuracy and recognition. The effect of accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
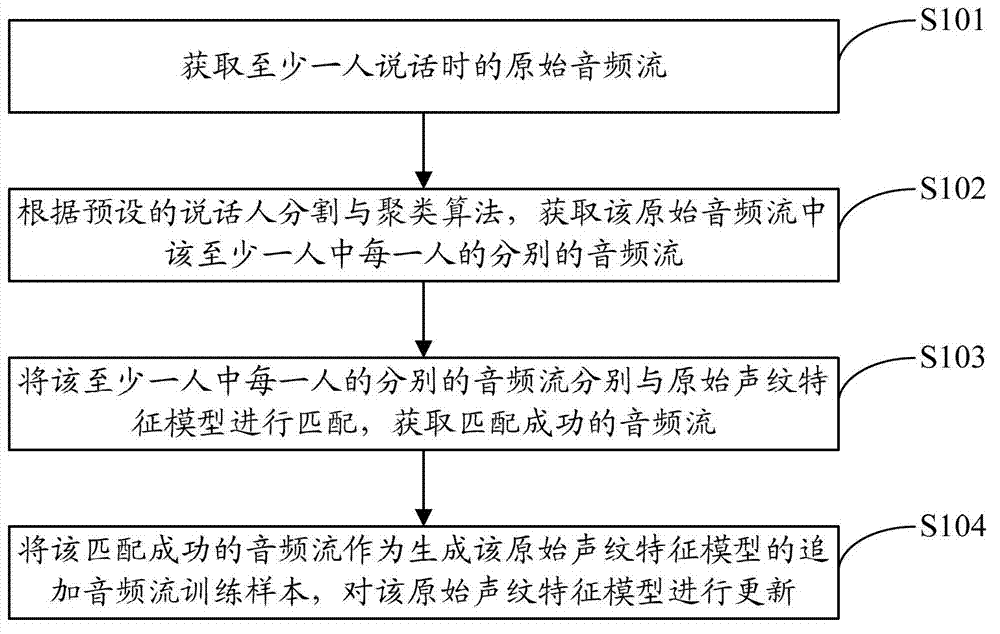
[0027] figure 1 The implementation flow of the method for updating the voiceprint feature model provided by the first embodiment of the present invention is shown, and the details are as follows:
[0028] In step S101, an original audio stream containing at least one speaker is obtained.
[0029] Wherein, the original audio stream may be an audio stream generated by the user through a mobile terminal to make a phone call, voice chat, etc., or may be an audio stream obtained by means of recording or the like. Specifically, when a mobile terminal user is connected to the phone, the user is prompted whether to agree to use the voiceprint learning function. After the user agrees, the audio stream generated during the speaking process is recorded; The switch to enable the voiceprint learning function during a call can be set by the user as needed; or the terminal is equipped with the voiceprint learning function, and the user can record the audio stream by himself. It should be n...
Embodiment 2
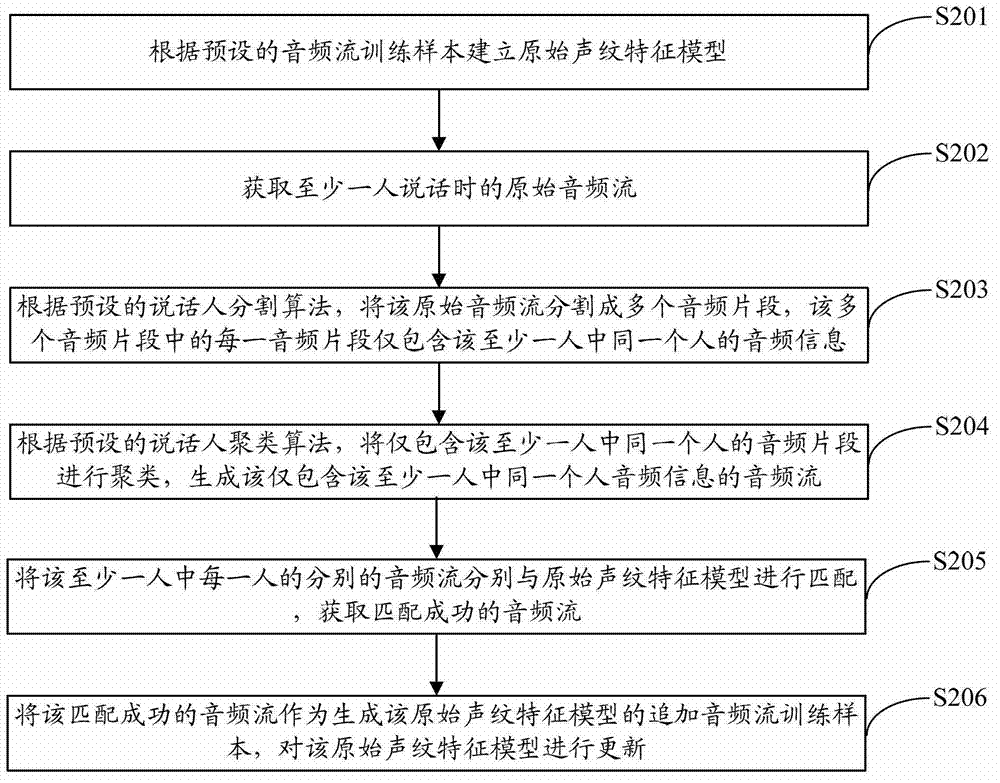
[0039] figure 2 The implementation flow of the method for updating the voiceprint feature model provided by the second embodiment of the present invention is shown, and the details are as follows:
[0040] In step S201, an original voiceprint feature model is established according to preset audio stream training samples.
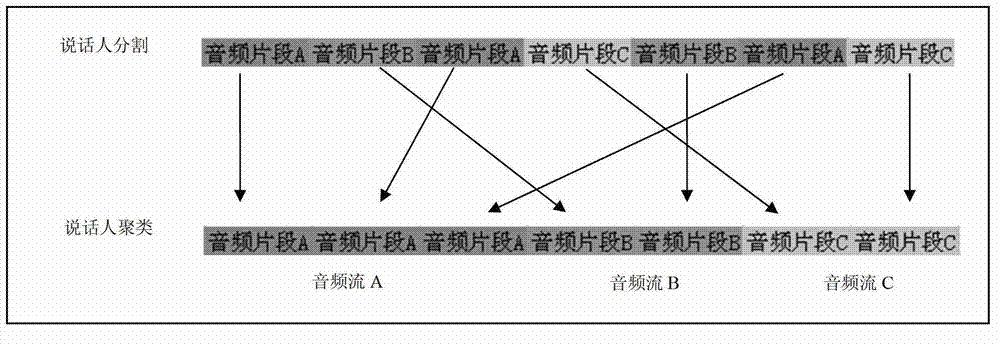
[0041] Wherein, the original voiceprint feature model is a voiceprint feature model established according to preset audio stream training samples by calling the voiceprint registration algorithm interface, and the original voiceprint feature model is a voiceprint registration completed for a certain person or multiple people The feature model formed after the registration process does not require the length of the training corpus or audio stream training samples. And because the method provided by the embodiment of the present invention can realize continuous dynamic correction of the corrected model, etc., the original voiceprint feature model can be a mo...
Embodiment 3
[0063] Figure 4 It shows the structure of the terminal provided by the third embodiment of the present invention. The terminal provided by the third embodiment of the present invention can be used to implement the methods realized by the first to second embodiments of the present invention. For relevant parts and specific technical details not disclosed, please refer to Embodiment 1 and Embodiment 2 of the present invention.
[0064] The terminal can be terminal equipment including mobile phone, tablet computer, PDA (Personal Digital Assistant, personal digital assistant), POS (Point of Sales, sales terminal), vehicle-mounted computer, etc. Figure 4 Shown is a block diagram of a partial structure of the mobile phone 400 related to the terminal provided by the embodiment of the present invention. refer to Figure 4 , the mobile phone 400 includes an RF (Radio Frequency, radio frequency) circuit 410, a memory 420, an input unit 430, a display unit 440, a sensor 450, an audio...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More