Index generation method and device for repeated data deletion
A technology of deduplication and generation device, which is applied in electrical digital data processing, special data processing applications, instruments, etc., can solve problems such as excessive amount of index information, save storage space, reduce the amount of index information, reduce The effect of reading and writing pressure
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
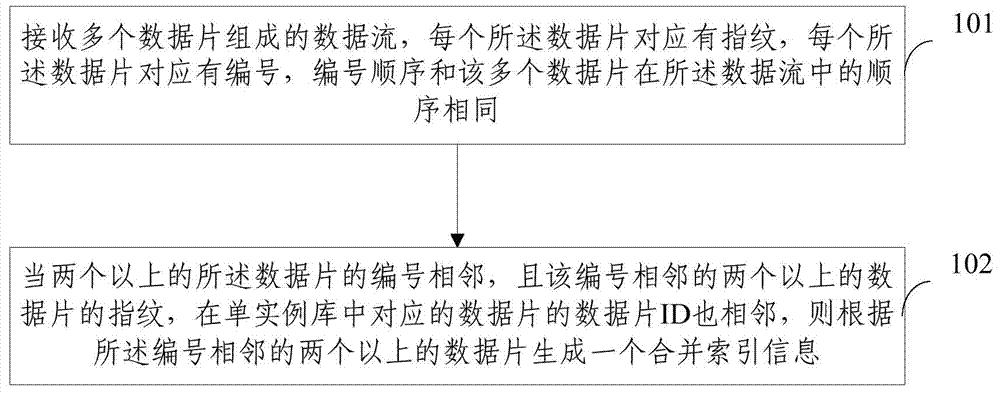
[0043] The first embodiment of the present invention provides a deduplication index generation method, the method flow chart is as follows figure 1 As shown, the method includes:
[0044] Step 101: Receive a data stream composed of a plurality of data slices, each of the data slices corresponds to a fingerprint, each of the data slices corresponds to a number, and the order of the numbers is the same as the order of the multiple data slices in the data stream ;
[0045] Step 102: When the numbers of two or more data slices are adjacent, and the fingerprints of the two or more data slices with adjacent numbers are also adjacent to the data slice IDs of the corresponding data slices in the single instance database, then generating a merged index information according to two or more data slices with adjacent numbers;
[0046]The single instance library includes a plurality of data units, each data unit stores a data piece and a fingerprint of the stored data piece, and the data...
Embodiment 2
[0055] In order to further improve the method provided in the first embodiment and to supplement the first embodiment, the second embodiment of the present invention provides an index generation method for deduplication to solve the problem of excessive index information. The flow chart of the method is as figure 2 As shown, the method includes:
[0056] Step 201: receiving a data stream composed of multiple data slices, wherein each data slice corresponds to a fingerprint, and each data slice corresponds to a serial number;
[0057] For example, a data stream F with a size of about 50KB includes 6 data slices with an average length of about 8K. Each data slice corresponds to a number 1, 2, 3, 4, 5, and 6. Multiple data slices are in the same order in the data stream, that is, data slice 1 (7K), data slice 2 (9K), data slice 3 (12K), data slice 4 (4K), data slice 5 (10K ) and data slice 6 (8K). The fingerprint of each data slice is used to identify the data slice. The data ...
Embodiment 3
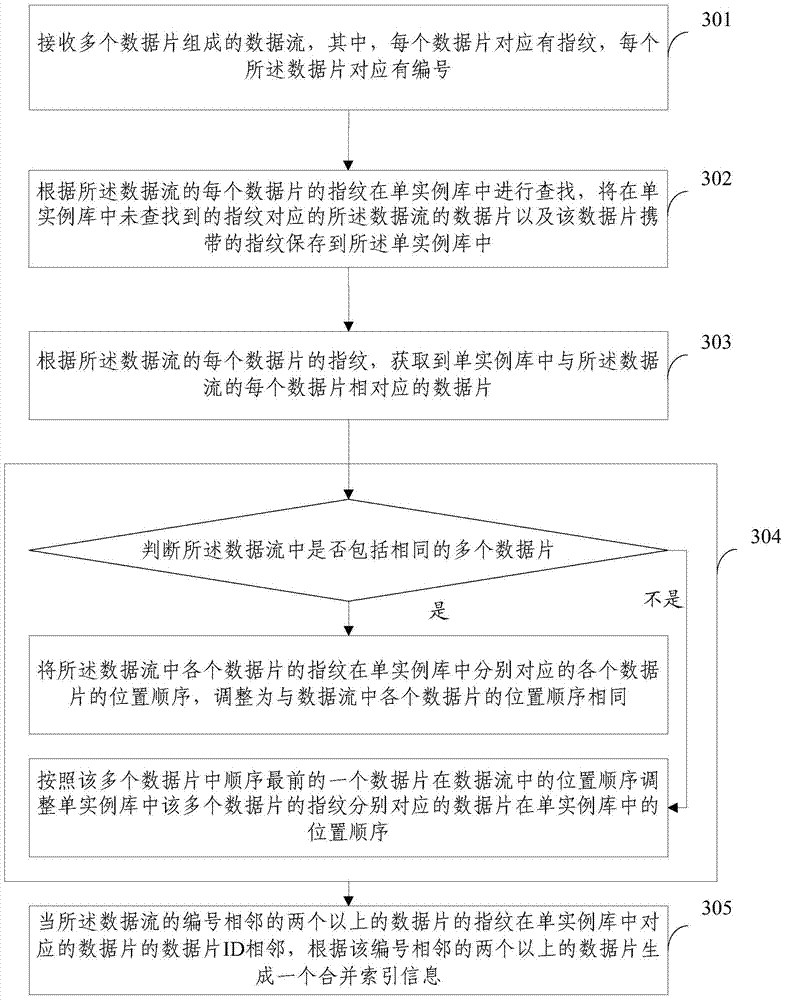
[0081] According to the method provided in Embodiment 1 or Embodiment 2, when the data slice in the single instance library corresponding to each data slice of the data stream is not indexed by any other data stream to create index information, and in order to further reduce the index information amount, the third embodiment of the present invention provides a deduplication index generation method, the method flow chart is as follows image 3 As shown, the method includes:
[0082] Step 301: Receive a data stream composed of multiple data slices, wherein each data slice corresponds to a fingerprint, and each data slice corresponds to a serial number;
[0083] This step 301 is the same as or similar to the step 201 of the second embodiment, and will not be repeated here.
[0084] Step 302: Search in the single-instance database according to the fingerprint of each data slice of the data stream, and find the data slice of the data stream corresponding to the fingerprint not fou...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More