

Self-adaptive incremental deep web data source discovery method
A deep network and discovery method technology, applied in the computer field, can solve problems such as difficulty in ensuring high coverage, low efficiency, and reduced crawling efficiency, and achieve the effect of increasing coverage, improving efficiency, and expanding sites
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0025] The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
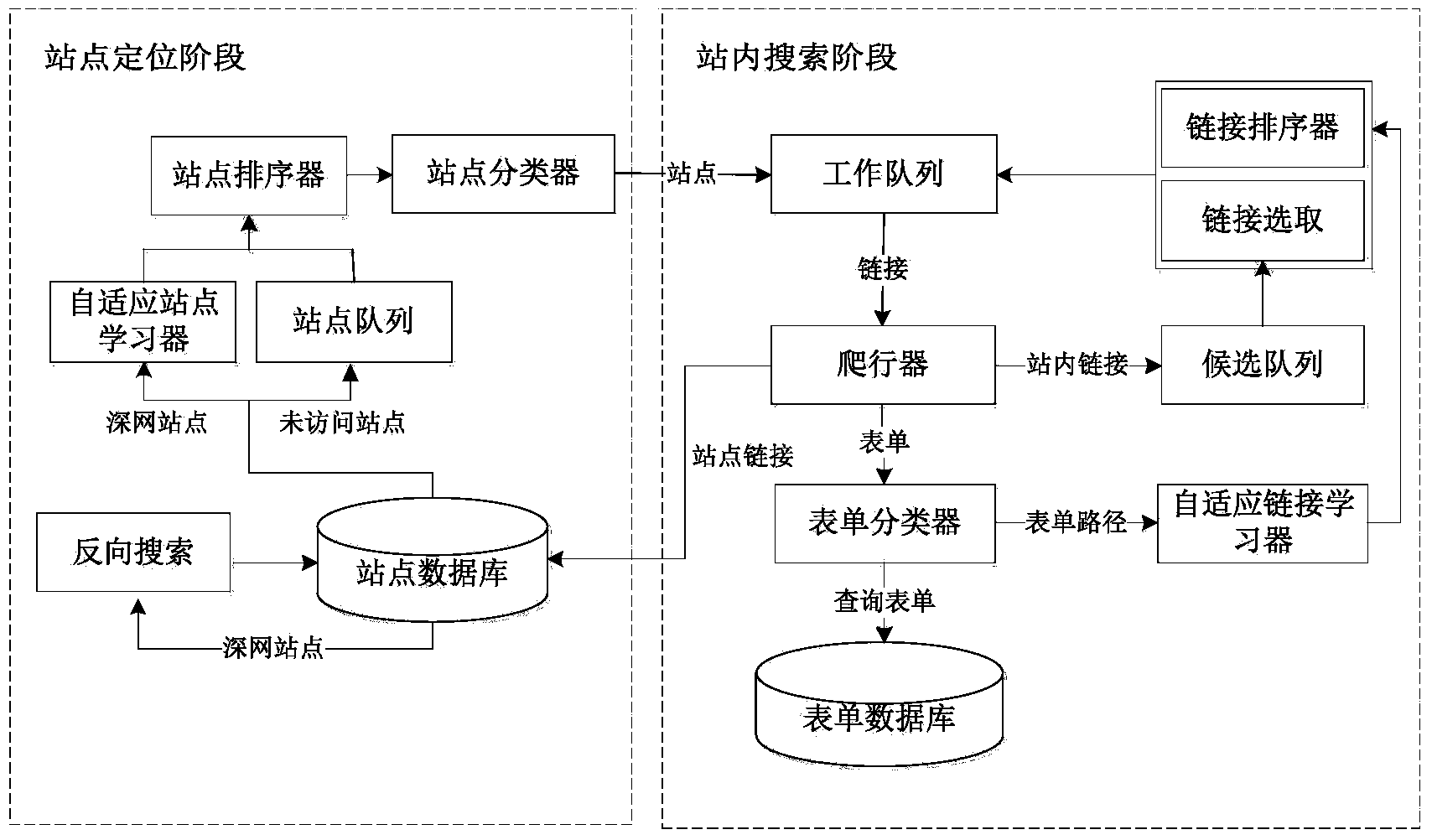
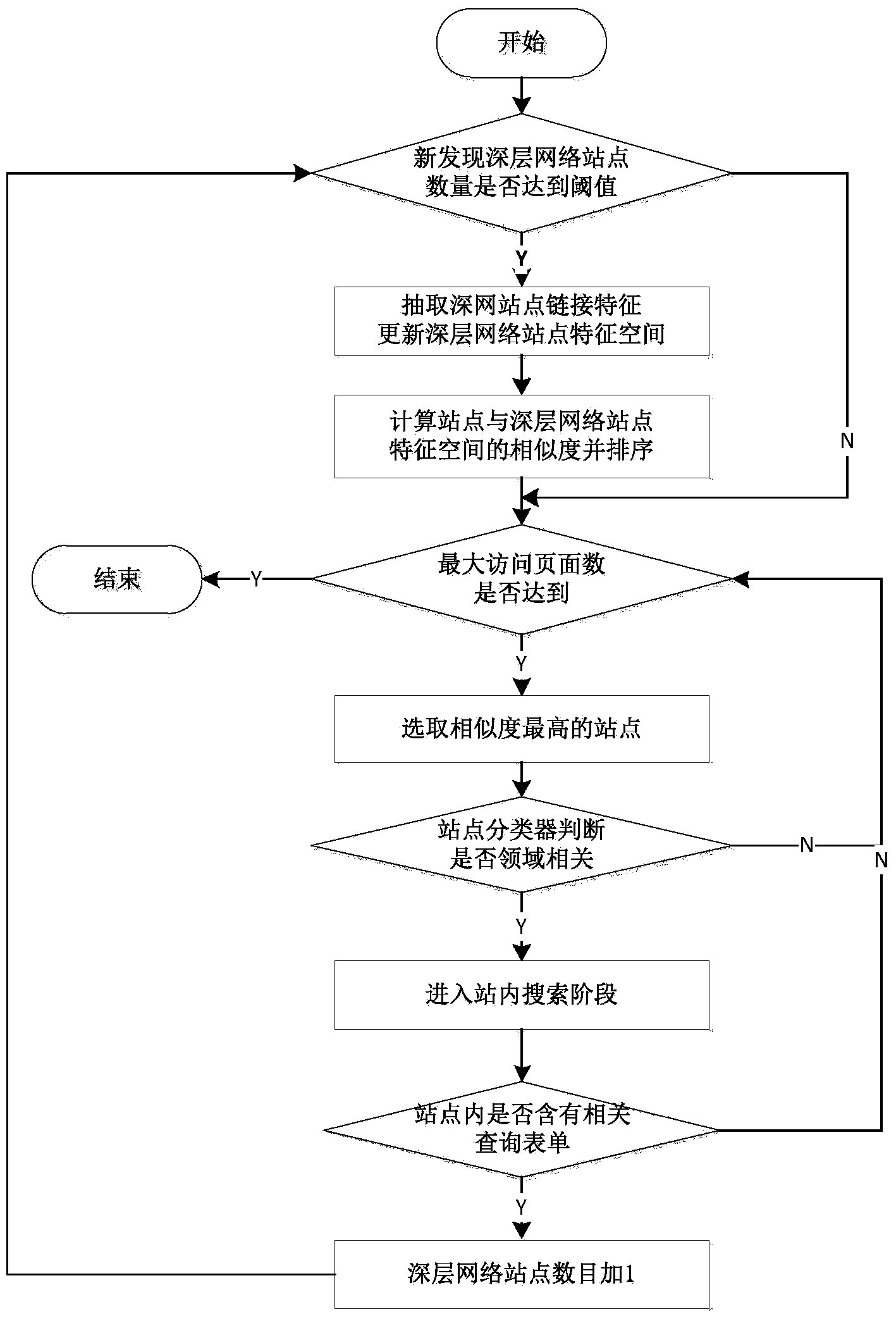
[0026] Such as figure 1 As shown, the self-adaptive incremental deep network data source discovery method of the embodiment of the present invention includes a site location stage and an in-site search stage.
[0027] (1) The stage of site location includes site collection, site sorting and site classification.
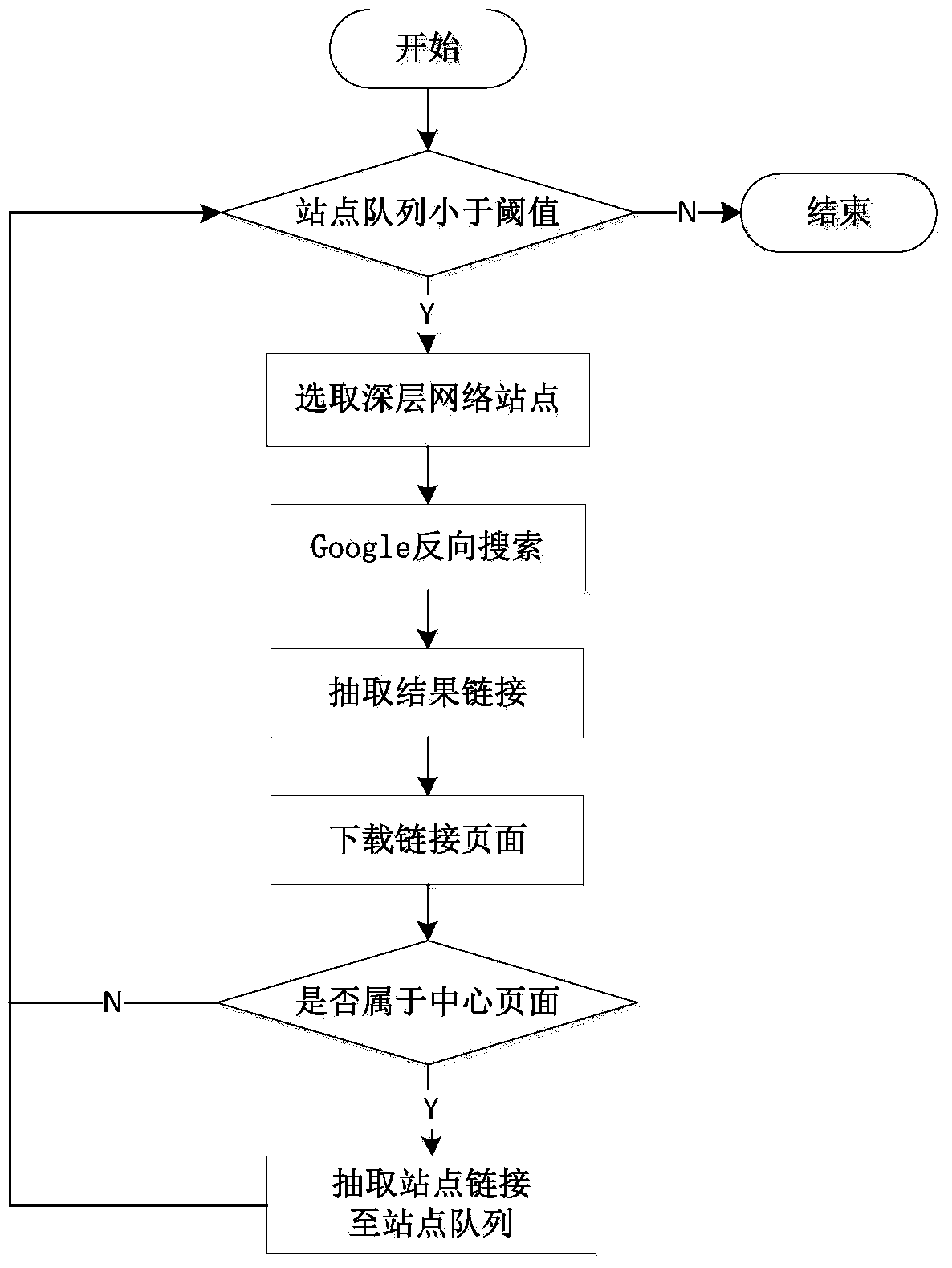
[0028] Site collection is used to discover new sites and ensure that there are sufficient site links in the site queue for selection during the crawling process. Such as figure 2 As shown, site collection includes the following steps:
[0029] (1-1) Judging whether the site queue size is smaller than the predefined threshold, if the condition is met, then go to step (1-2); otherwise, end directly;
[0030] (1-2) Submit the discovered deep network sites as input to the search engine for reverse search, then extract the links in the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More