

Rapid mass data cluster processing method for computer
A technology of massive data and processing methods, applied in the field of data processing, to achieve the effect of reducing computational complexity, convenient, fast and effective processing, and good structure
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

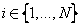
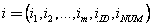
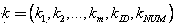
Examples
Embodiment Construction
[0028] The object of the present invention is to provide a kind of fast massive data clustering processing method of computer with data profile analysis ability, described method is for the number of The data objects to be clustered, after The clustering results of any number of clusters can be obtained by combining calculations once, and the specific composition of the data objects contained in each sub-category and the centroid of the sub-category (that is, the arithmetic mean of the attribute values of the contained data objects) can be obtained. It has the characteristics of fast calculation speed and strong data analysis ability.
[0029] In order to achieve the above object, the technical solution adopted in the present invention comprises the following steps:
[0030] Step 1. Data object preprocessing. For all data objects to be analyzed (the number is ) for preprocessing, the specific method of preprocessing is: for any given data dimension is The data obje...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More