

Dialogue short text clustering method based on form and semantic similarity
A semantic similarity and short text technology, applied in text database clustering/classification, unstructured text data retrieval, instrumentation, etc., can solve problems such as short text cannot be handled well, prominent, single topic, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
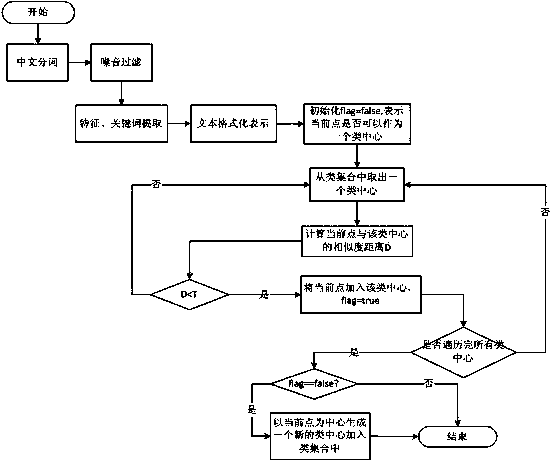
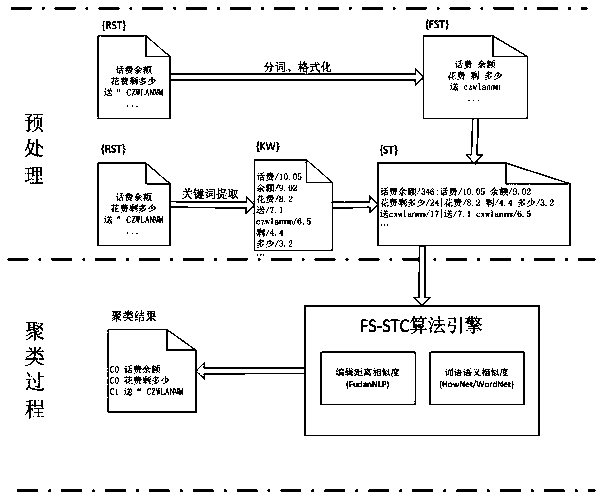
[0031] The present invention can effectively cluster short dialogue texts. The following takes the dialogue text provided by Xiaoi robot as an example, combined with the attached figure 2 The present invention is further described.
[0032] The implementation process mainly includes two stages. The first stage is to filter and preprocess the original text data, such as text length filtering, Chinese word segmentation, and unification of English strings, and then use the keyword extraction tool to obtain keywords and weights; In the second stage, the short text collection is clustered using the morphology of strings and the semantic similarity of words, which is the process of FS-STC clustering method.
[0033] 1). Preprocessing stage
[0034] If the text set that needs to be clustered is a short Chinese text, it is first necessary to use the word segmentation tool to segment the short text, and use the Chinese Academy of Sciences 2014 word segmentation tool to segment the t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More