Spoken language pronunciation detecting and evaluating method based on deep neural network posterior probability algorithm
A deep neural network and posterior probability technology, applied in the field of oral pronunciation evaluation based on deep neural network algorithm, can solve problems such as time-consuming
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

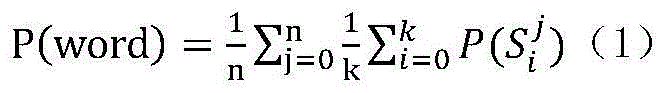
Examples
Embodiment 1
[0041] Deep neural network algorithm (DNN) is a new hot topic in the field of machine learning in industry and academia in recent years. The DNN algorithm has successfully improved the previous recognition rate to a significant level. Moreover, most current speech recognition systems use Hidden Markov Models (HMMs) to deal with real-time changes in speech, use Gaussian mixture models to determine how well each state of each HMM model matches acoustic observations, and another method to evaluate the matching The degree method is to use a feedforward neural network (NN), and the deep neural network (DNN) is a neural network with more hidden layers. The DNN method has been proved to be better than the Gaussian mixture model in various speech recognition. The benchmark performance has been greatly improved.
[0042] From the traditional oral pronunciation evaluation method, we can see that to improve the quality of the oral evaluation algorithm, we need a high-quality acoustic mo...
Embodiment 2
[0056] According to this embodiment, the specific solutions of the above embodiments will be described in more detail.
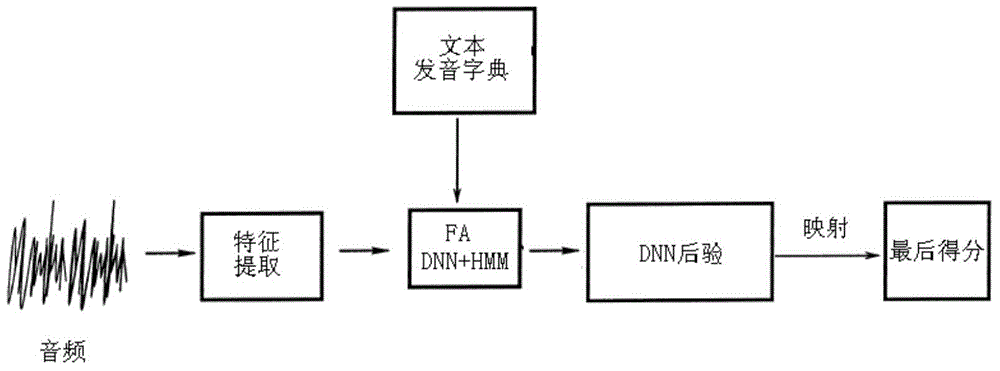
[0057] First, the speech is extracted frame by frame as a sequence of feature vectors.
[0058] Common speech features include Perceptual Linear Prediction (PLP) and Mel Cepstral Coefficient (MFCC) features. Then, according to the trained acoustic model DNN+HMM, the given oral evaluation text, and the corresponding word pronunciation dictionary, the time boundary of the phoneme state is determined through the Viterbi algorithm.
[0059] After determining the time boundary, extract the DNN posterior probability corresponding to all frames in the time boundary, and take the average value according to the frame length as the posterior probability of the phoneme state, so we have the word posterior score calculation based on the phoneme state posterior plan:
[0060] P ( word ) = ...
Embodiment 3
[0073] To sum up, our oral evaluation algorithm based on DNN posterior is as follows:
[0074] Step 1: Extract audio features.
[0075] Step 2: Input the audio features into the pre-trained DNN+HMM model, and use the Viterbi algorithm to determine the phone boundary of the sentence read by the speaker and the corresponding DNN posterior probability according to the given text and pronunciation dictionary.
[0076] Step 3: Calculate the word-level score using formula (1)
[0077] Step 4: Calculate the sentence-level score using formula (2)
[0078] Step 5: Finally, the word-level and sentence-level posterior scores are mapped to the required score segments through a preset mapping function.
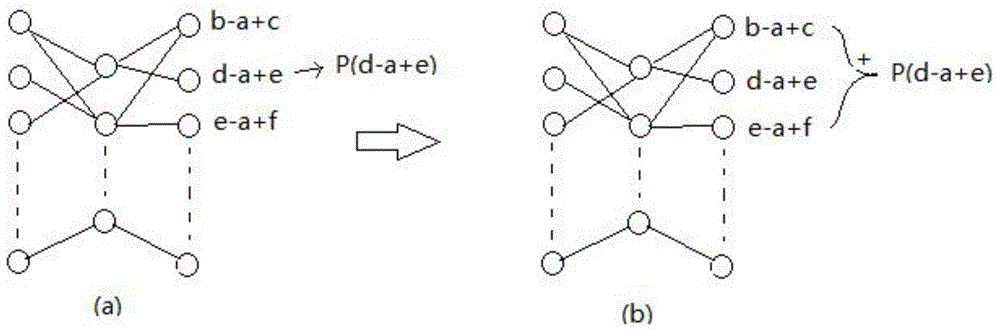
[0079] In addition, in the above steps, in steps 3 and 4, the posterior probability of the phoneme state can adopt the following optimal calculation scheme:
[0080] According to the centralphone posterior probability calculation scheme, the posterior probability of each phoneme state i...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



