

Characteristic extraction method of text classification on the basis of mutual information
A feature extraction, mutual information technology, applied in special data processing applications, instruments, electrical digital data processing and other directions, can solve problems such as difficult text processing
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

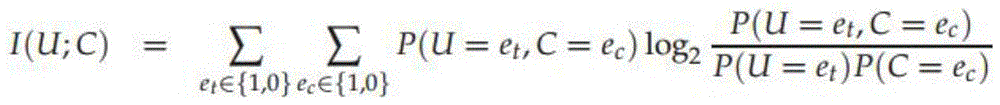
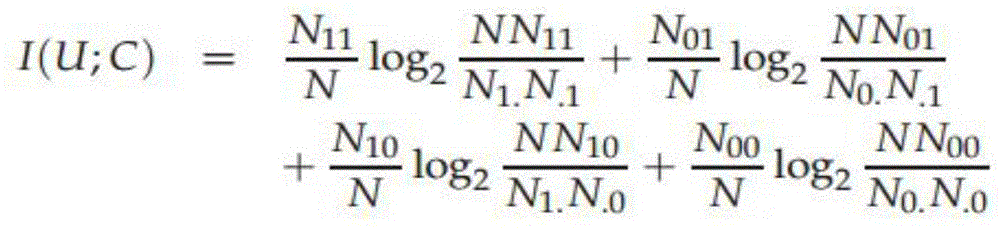
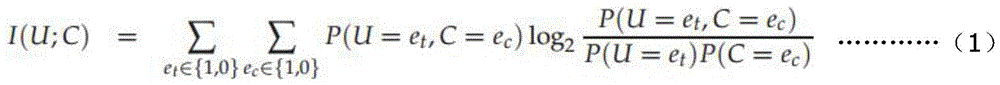
Examples
Embodiment Construction
[0025] Specific embodiments of the present invention will be described below.
[0026] A kind of feature extraction method of text classification based on mutual information provided by the present invention, comprises the following steps:
[0027] 1) Obtain a certain number of articles of various categories from crawlers on the Internet as a training data set for the text classification system;
[0028] 2) Preprocessing the training text: Segment the training data set. The word segmentation tool used is Stutter Segmentation, which is an open source Chinese word segmentation module developed by Python. Afterwards, these stop words are filtered out according to the stop word lexicon. , use the stutter module to tag the text after word segmentation.
[0029] 3) Feature extraction of the preprocessed text: according to (2) the preprocessed text, only the words whose parts of speech are nouns and verbs are left, which is the initial feature extraction. Calculate the remaining te...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More