

An implementation method of an analysis model supporting massive long text data classification
An analysis model and data classification technology, which is applied in text database clustering/classification, unstructured text data retrieval, electronic digital data processing, etc., to achieve wide application prospects, improve algorithm efficiency, and reduce time complexity.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0014] The present invention will be further described in detail with reference to the accompanying drawings and embodiments.
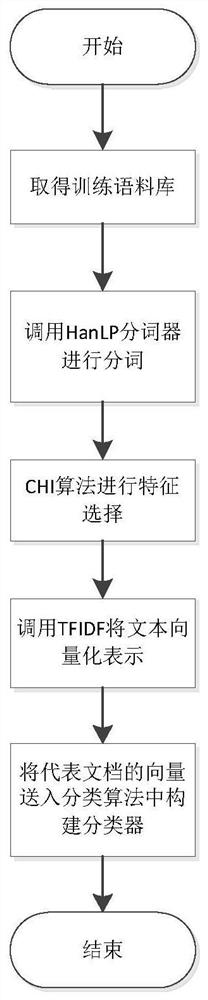
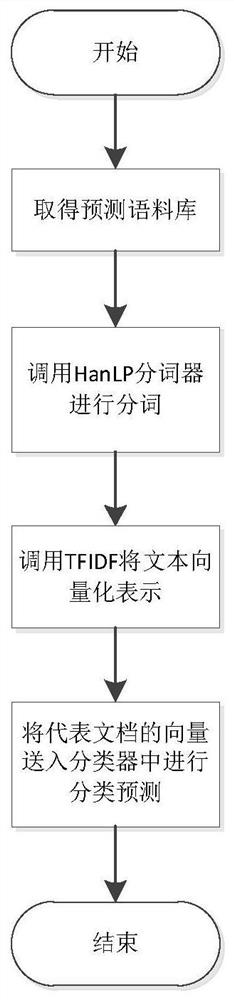
[0015] The present invention provides an analysis model supporting the classification of massive long text data and its implementation method. The analysis model adopts a text classification algorithm based on statistics. The text classification algorithm adopts a vector space model (VSM), and extracts from the CHI algorithm. According to the TFIDF algorithm, the category feature words realize the vectorized representation of the text, and use the naive Bayesian method to train the corpus, and realize the analysis model for the classification of massive long text data.
[0016] The analysis model is realized through the following steps:
[0017] The first step is to establish a VSM-based statistical classification model to represent the text in a vectorized manner.
[0018] Because the situation of directly processing natural language is too complica...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More