

Duplicated data detecting method based on clustering
A technology of repeated data and detection methods, which is applied in electrical digital data processing, special data processing applications, instruments, etc., can solve the problems of inability to detect repeated data in large data sets and low detection performance, and achieve the effect of narrowing the scope and improving performance.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
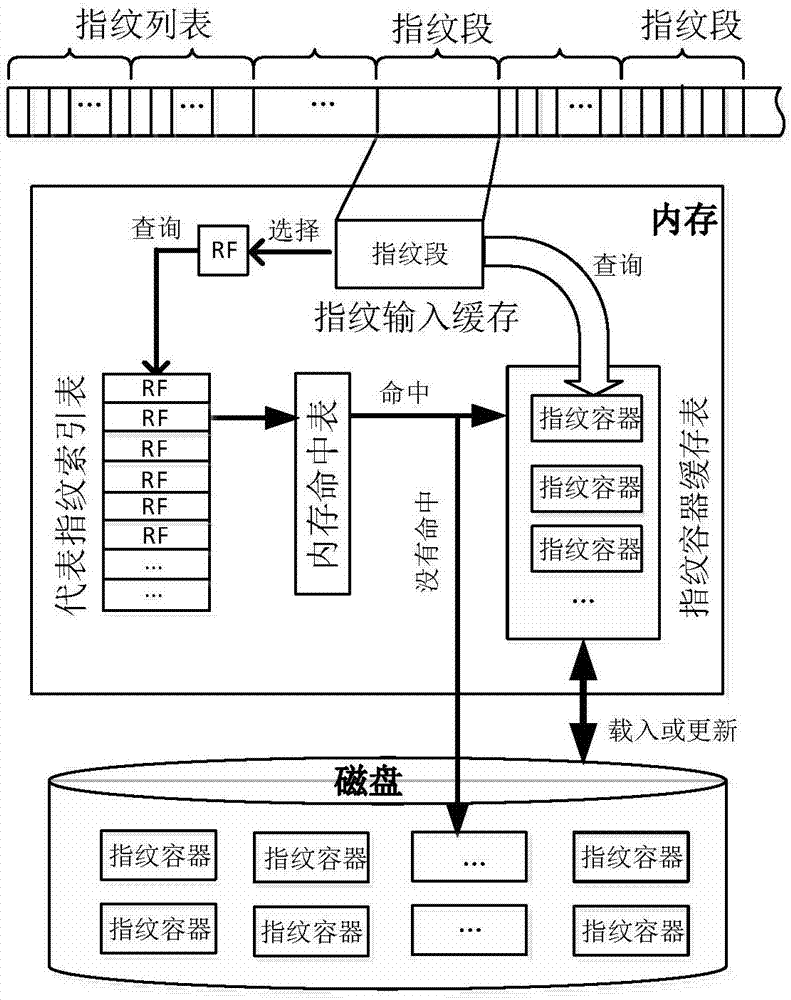
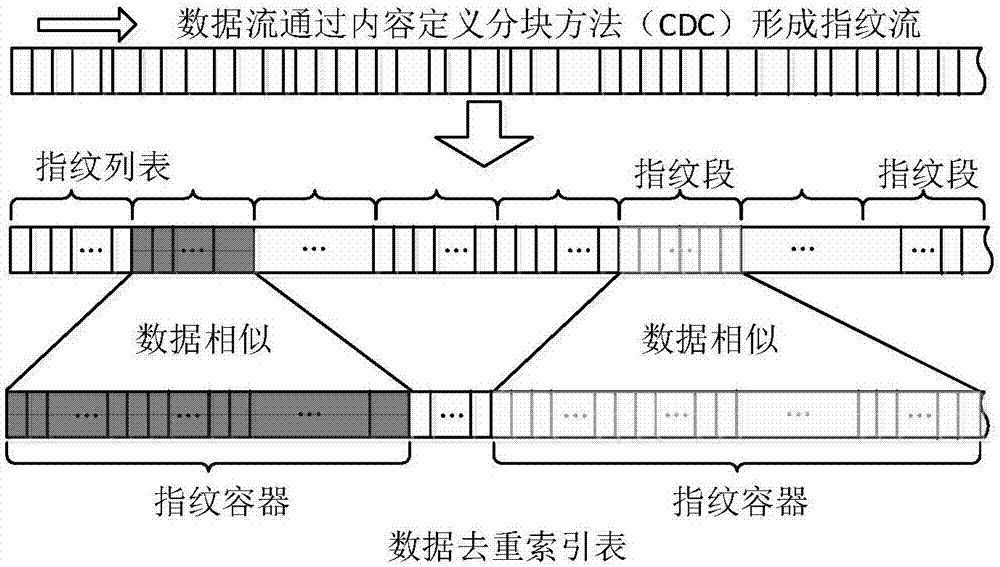
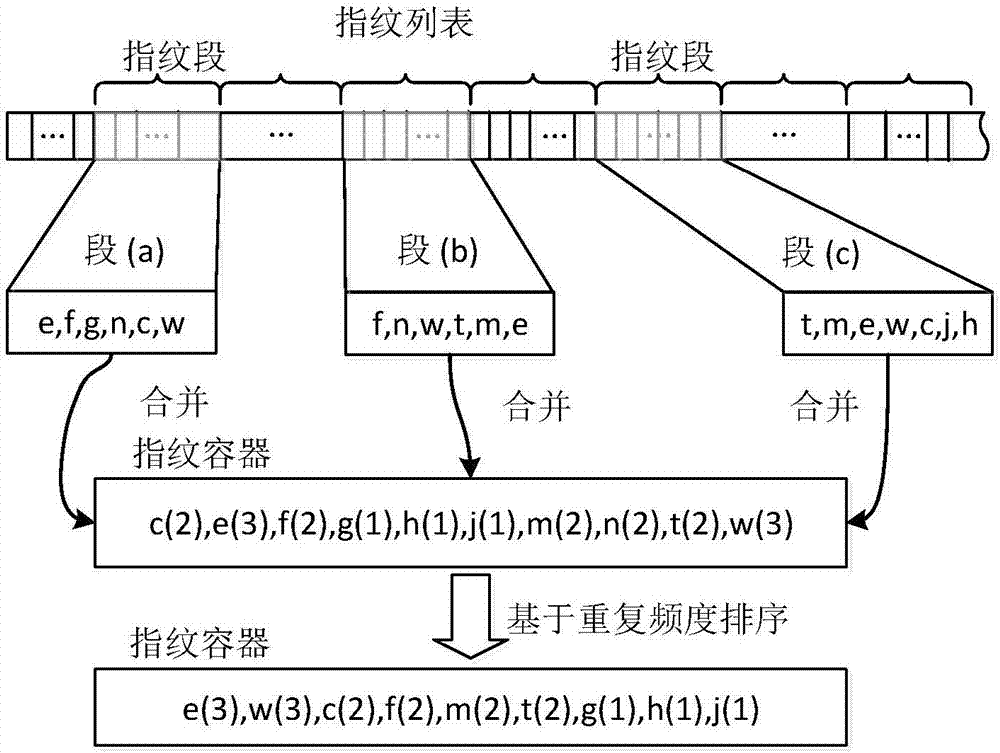
[0042] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention. In addition, the technical features involved in the various embodiments of the present invention described below can be combined with each other as long as they do not constitute a conflict with each other.
[0043] The present invention provides an efficient clustering-based duplicate data detection method. The method mainly faces data sets with strong similarity, and stores similar data in the data set together through similarity principles and clustering ideas to solve the problem of The problem of low detection efficiency in existing duplicate data detection methods is to adapt to the status quo ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More