A clustering method based on big data
A clustering method and big data technology, applied in the field of clustering analysis, can solve the problems of reducing the speed of search efficiency, affecting the efficiency of retrieving user target information, etc., to achieve the effect of improving accuracy and effectiveness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

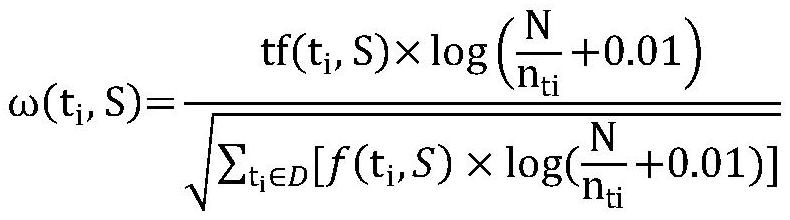
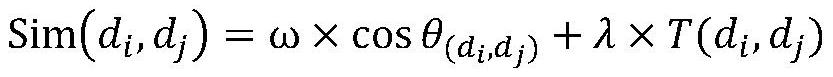
Examples
Embodiment Construction
[0028] In order to have a clearer understanding of the technical features, purposes and effects of the present invention, the specific implementation manners of the present invention will now be described with reference to the accompanying drawings.
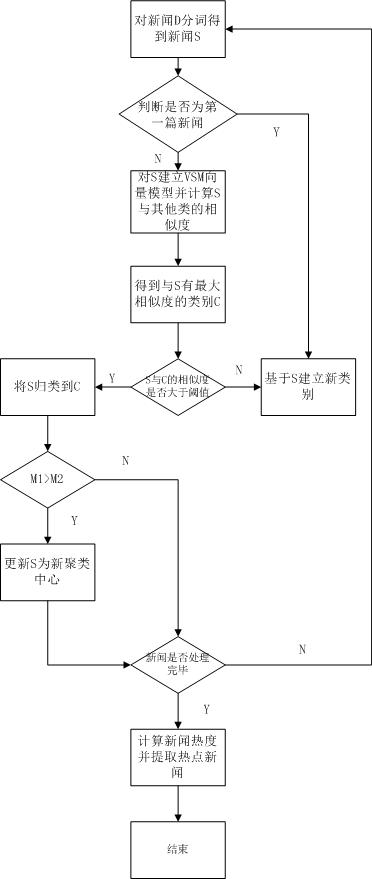
[0029] Such as figure 1 As shown, a clustering method based on big data includes the following steps:
[0030] S1. Segment news D to obtain news S;
[0031] S2. Determine whether the news S is the first news, if so, execute S5, if not, execute S3;
[0032] S3. Establish a VSM vector model for the news S, and calculate the similarity between the news S and all categories of the cluster center;
[0033] S4. find out the category C with the maximum similarity with the news S, if the similarity between the news S and the category C is greater than a preset threshold, then classify the news S into the category C, If it is less than the preset threshold, execute S5;
[0034] S5. Create a new category based on the news S;
[0035] ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com